Snowflake Universal AI Catalog: The Semantic Layer Is Critical Infrastructure
Snowflake's Universal AI Catalog embeds governance, semantic context, and lineage directly into the data path. Here is why this validates the bottom-up approach to AI readiness.

Snowflake just made the strongest case yet that data governance is not a compliance checkbox. It is the foundation that determines whether AI agents can actually work. Their Snowflake Universal AI Catalog, built on the Horizon Catalog platform, embeds semantic context, lineage, and access control directly into the data path. Not as an afterthought. As the architecture itself.
This matters because most organizations are still treating governance as a separate workstream from AI. Snowflake is telling the market: they are the same workstream. And if you have been following the Intelligence Allocation Stack framework, this is Layer 1 and Layer 2 working exactly as designed.

What Snowflake Actually Announced
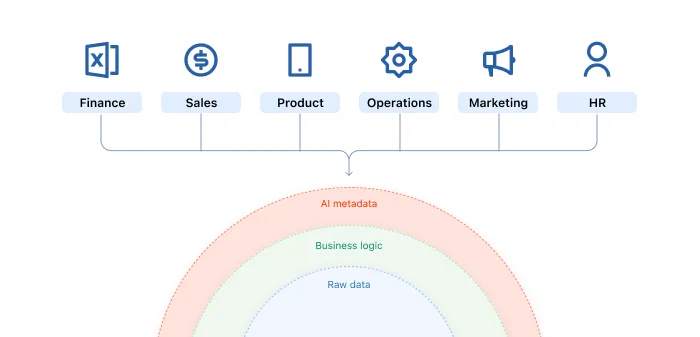
The Universal AI Catalog is Snowflake's answer to a problem every data team knows. Metadata sits in dozens of tools. Business logic lives in people's heads. AI models get raw tables with no context about what the data means or who should access it.
Horizon Catalog solves this by creating a single governance layer that spans Snowflake's native environment and external data platforms through Apache Polaris and Iceberg REST APIs. The key features tell a clear story about where the industry is heading.
Semantic Views let teams define business logic once and compile it into any query engine. Think of it as a universal translation layer. Your definition of "revenue" or "active customer" gets embedded into the catalog and follows the data wherever it goes. This is the semantic layer made portable.
Universal data lineage tracks how data flows across Snowflake, Iceberg, and connected platforms. When an AI agent queries a metric, it can trace exactly where that number came from. No black boxes.
Data quality monitoring runs continuously, flagging issues before they reach a dashboard or an AI model. Bad data in means bad decisions out. Snowflake is building the quality gate directly into the catalog.
Governance controls include RBAC, ABAC, row-level security, and sensitive data protection that travels with the data. Not applied at the tool level. Applied at the data level. That distinction matters enormously for AI agents that pull from multiple sources.
Why This Validates the Bottom-Up Approach
For every dollar companies spend on AI, they should be spending six on the data architecture underneath it. That is the core thesis behind the Intelligence Allocation Stack. And Snowflake just built a product that proves why.
Layer 1 of the stack is the Data Foundation. Governance, quality, ingestion, warehousing, single source of truth. Layer 2 is the Semantic Layer. Business logic translated for machines, metric definitions, governed vocabulary. The Snowflake Universal AI Catalog is both layers fused into one platform.
The reason this matters is simple. AI agents do not understand business context by default. They need a governed semantic layer to know that "revenue" in the finance team's model means the same thing as "revenue" in the marketing dashboard. Without that translation layer, you get agents that confidently deliver wrong answers.
88% of companies use AI today. Only 39% see measurable impact. The gap is not the models. The gap is the data architecture underneath them. Snowflake is now building the product to close that gap.

Snowflake vs Databricks: Two Approaches to the Same Problem
Databricks Unity Catalog was first to market with a unified governance solution. It works well inside the Databricks ecosystem. Spark, Delta Lake, MLflow. If your entire stack lives there, Unity delivers real value.
Snowflake's Horizon Catalog takes a different bet. Universal reach over ecosystem lock-in. Through Apache Polaris and the Iceberg REST protocol, Horizon extends governance to data that lives outside Snowflake entirely. That is a meaningful architectural difference.
Most enterprises do not run a single-vendor stack. They have Snowflake for warehousing, dbt for transformations, Fivetran for ingestion, and multiple BI tools on top. A governance layer that only works inside one ecosystem leaves gaps. Gaps that AI agents will exploit, not because they are malicious, but because they follow the path of least resistance to an answer.
The comparison comes down to philosophy. Databricks says: bring everything into our platform and we will govern it. Snowflake says: keep your architecture, and we will extend governance to wherever your data lives. For organizations running a modern data stack with multiple best-of-breed tools, the second approach removes more friction.
Cortex Code and the Natural Language Governance Layer
One feature deserves special attention. Cortex Code lets teams interact with governance through natural language. Instead of writing complex SQL to check lineage or set access policies, you describe what you need in plain English.
This lowers the barrier for data governance adoption. The biggest blocker to governance is not technology. It is that governance workflows are tedious enough that teams skip them. When you can say "show me every dashboard that uses this revenue metric" instead of tracing lineage manually, governance becomes something people actually do.
For AI agents specifically, Cortex Code creates a natural language interface to the catalog itself. An agent can query the catalog to understand what data is available, what it means, and whether it has permission to use it. That is the missing piece between "we have AI" and "our AI delivers trustworthy results."
What This Means for Your Data Strategy
Snowflake's announcement confirms a pattern that has been building for two years. The semantic layer is no longer optional infrastructure. It is the control plane for AI.
If you are running a modern data stack today, here is what to take from this.
Governance and AI readiness are the same initiative. Stop running them as separate projects. Every governance decision you make now directly impacts what your AI agents can do next quarter.
The semantic layer is your competitive moat. Tools change. Models improve. But the business logic layer that translates raw data into trusted metrics is what makes AI actually useful in your specific context. Invest there.
Start at Layer 1, not Layer 4. The companies seeing real ROI from AI are the ones that fixed their data foundation first. Not the ones that bought the most expensive model. Snowflake is building products for these companies because that is where the market is heading.
Open standards win. Apache Iceberg, Polaris, and REST APIs are the connective tissue. Snowflake betting on open interoperability over proprietary lock-in signals that the modern data stack architecture is here to stay. Pick tools that play well with others.
Gartner predicts 60% of AI projects will be abandoned due to data not being AI-ready. The Snowflake Universal AI Catalog is a direct response to that statistic. The question for data leaders is not whether to build this foundation. It is whether to build it now or watch competitors do it first.
The Bottom Line
Snowflake's Universal AI Catalog is not just a product announcement. It is a market signal. The largest cloud data platform in the world is telling every data leader the same thing: your AI strategy is only as strong as your governed semantic layer
Fix the floor before you let the agents run. That has always been the framework. Now Snowflake is building the floor.
More on Data Governance
Get actionable insights on this topic — and more — straight to your inbox. No fluff.

More from Unwind Data

What is Data Governance? The Complete Guide for Modern Data Teams
Data governance is the set of policies, processes, and standards that ensure your organization's data is accurate, consistent, secure, and usable by both humans and AI systems.
Data Governance for AI: The Foundation Your Models Need
Data governance for AI ensures your models, agents, and automations run on trusted, consistent data. Learn what it takes to build a governance layer that makes AI reliable.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch