Enterprise AI Is Stalling on a Data Foundation Almost Nobody Has Built
Only 7% of enterprises say their data is completely ready for AI. The Cloudera and HBR 2026 report confirms what the 60% AI project failure rate has been screaming: the bottleneck is the data foundation, not the model.

Only 7 percent of enterprises say their data is completely ready for AI. That number comes from a March 2026 report by Cloudera and Harvard Business Review Analytic Services, surveying more than 230 leaders directly involved in AI data decisions inside their organizations. Twenty-seven percent admit their data is not very ready, or not ready at all. The remaining two-thirds sit somewhere in the murky middle, where most failed AI projects are quietly buried.
If you have been paying attention to the data infrastructure conversation, none of this is news. It is just confirmation, with a sharper number than usual.
The Real Constraint Is Not the Model
Every quarter a new model release sets a new benchmark. Every quarter another wave of enterprise leaders convince themselves that capability is the bottleneck. It is not. The bottleneck is, and has been for years, the data foundation underneath the model.
The Cloudera and HBR report is unusually direct about this. Only 23 percent of organizations have an established data strategy for AI adoption. Another 53 percent are actively developing one. That means three-quarters of enterprises are still building the runway while the planes are already taxiing. The result is exactly what Gartner has been predicting: through 2026, organizations will abandon roughly 60 percent of AI projects that lack AI-ready data.
This is not a model problem. It is a data infrastructure problem.
What AI-Ready Data Actually Means
The phrase 'AI-ready data' gets thrown around so casually it has started to lose meaning. Strip away the marketing and it comes down to four things.
First, the data has to exist somewhere governed. Not in a spreadsheet on someone's desktop, not in an undocumented Postgres table that only one analyst understands, not in a SaaS tool that nobody has connected to the warehouse. Governed means the data has an owner, a definition, and a lineage that can be traced.
Second, the business logic has to live in a semantic layer that machines can read. If your definition of 'active customer' exists in the head of your VP of Sales but nowhere in your data architecture, no AI agent will give you a trustworthy answer to a question about active customers. It will give you a confident answer, which is worse.
Third, the data pipelines have to be reliable. If your data is fresh on Tuesday and stale on Wednesday because a Fivetran connector quietly failed, your AI is making decisions on yesterday's reality. Data pipelines that nobody monitors are not pipelines. They are liabilities.
Fourth, the data has to be accessible across environments without compromising governance. The biggest unlock for AI agents is not raw model power. It is the ability to read clean, governed data from across the business, on demand, with permissions that respect who is asking.
When you put those four things together, you have what the Cloudera report calls AI readiness. Seven percent of enterprises have it. Everyone else is improvising.
The Pattern Is Decades Old
I wrote a Medium article in 2019 predicting that every company was about to start hiring Data Engineers to clean up the mess that the dashboard era had created. I could rewrite that article in 2026 with almost no edits. The only change would be the name of the layer at the top. In 2019 the mess was business intelligence dashboards built on broken pipelines. In 2022 the mess was data scientists building models on data nobody trusted. In 2026 the mess is AI agents being pointed at warehouses that were never designed to feed them.
The pattern is always the same. A new layer of intelligence arrives at the top of the stack. Companies rush to deploy it. They skip the foundation. The foundation breaks. They hire engineers to fix it. Twelve months later they are roughly where they should have started.
This is what I call allocating intelligence to the wrong layer. For every dollar an enterprise spends on AI, six should go to the data architecture underneath it. Most enterprises are doing the opposite. They are putting six dollars into the model layer for every dollar going into the data foundation. Then they are surprised when the agent gives a confident wrong answer.
Why Governance Is the New Bottleneck
The Cloudera report ranks the most critical components of an AI data strategy. Protecting sensitive data and privacy comes first at 59 percent. Data quality follows at 46 percent. Data governance lands at 41 percent. Read those three together and you are reading the same word three different ways: governance.
This is what changes when you move from dashboards to agents. A dashboard reads data and shows it to a human, who then decides what to do with it. An agent reads data and acts on it. The human in the middle is gone. Every weakness in your data governance is now a weakness in your decision-making, at machine speed, with no review.
If your current data governance is strong enough for dashboards but not for autonomous systems, the gap will not stay hidden for long. An AI agent making purchasing decisions on incomplete vendor data will burn money before anyone notices. An AI agent answering compliance questions from an ungoverned semantic layer will create legal exposure before legal even sees the question.
This is the part that the 7 percent figure does not capture. The other 93 percent are not just unprepared. They are exposed.
Start at One, Not at Four
The Intelligence Allocation Stack has four layers. The data foundation. The semantic layer. The orchestration layer. The AI layer. The order matters. You build bottom-up, never top-down.
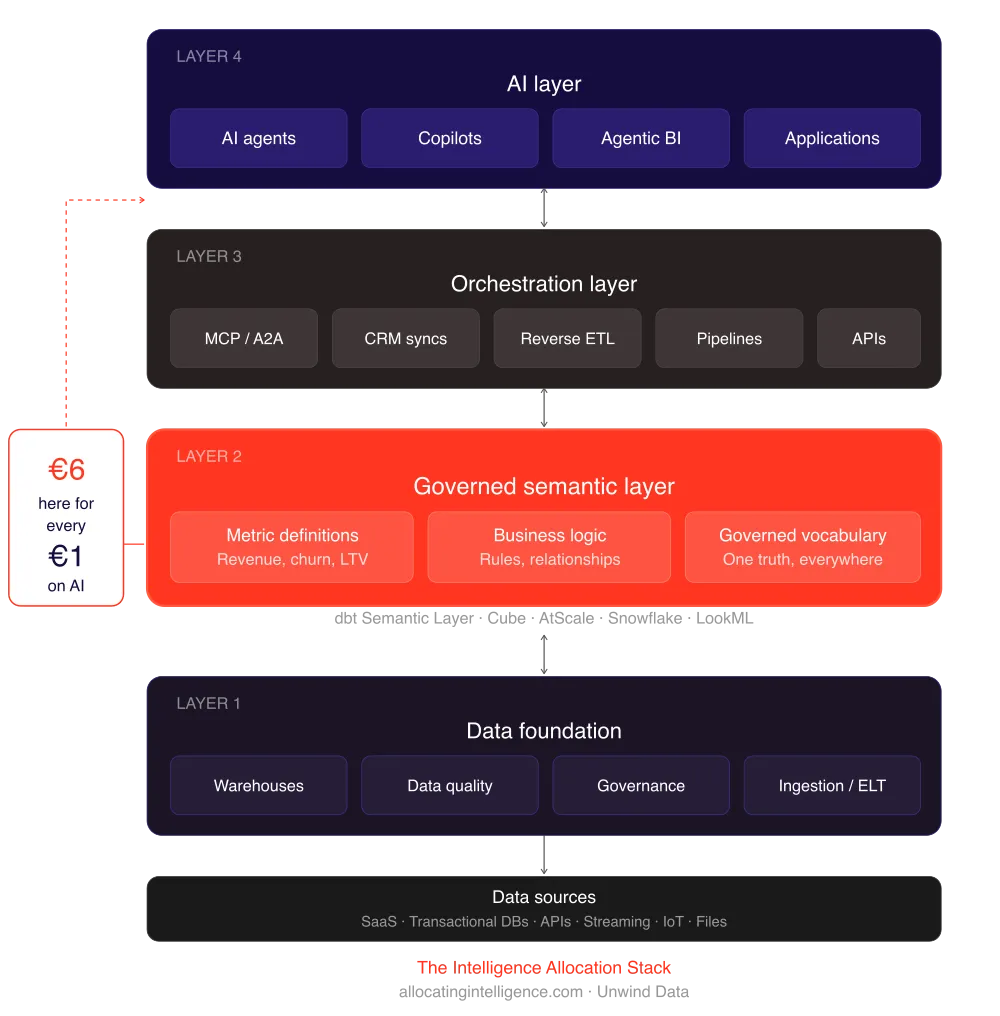
The temptation in 2026 is to start at layer four. Pick a model, deploy an agent, see what happens. The temptation is understandable because the AI layer is where the demos live. The demos are dazzling. The board wants to see them. The competitor down the street is shipping them. So you skip the foundation, deploy at layer four, and end up in the 60 percent of AI projects that Gartner expects to be abandoned.
The 7 percent who get this right are doing something boring. They are fixing layer one. They are auditing their data pipelines, governing their warehouse, defining their metrics in a semantic layer that lives in code, and only then building the agents on top. The boring work is the work that compounds. The exciting work is the work that gets quietly deprecated next quarter.
What This Means for the Next Twelve Months
The gap between the 7 percent and the 93 percent is going to widen in 2026, not narrow. The companies with a real data foundation will deploy AI that actually moves a number on the income statement. The companies without one will run pilots that never reach production, write off the cost as 'learning,' and try again with a different vendor.
The CIOs and Heads of Data who understand this are quietly making different choices. They are slowing down the AI rollout to speed up the data foundation. They are spending the dollars on dbt, Snowflake, BigQuery, Looker, Omni, and whatever orchestration layer fits their stack, before they spend a euro on agents. They are picking governance vendors for the long game, not the demo. They are making the work boring on purpose, because boring work is the only kind that scales.
Systems beat individuals at scale. That has been the rule for every wave of enterprise technology, and AI is not the exception. It is the loudest example yet.
The Question to Ask This Quarter
If you are sitting inside a company that is investing in AI right now, the question is not which model to use. The question is whether your data foundation could survive that model being pointed at it. Could your data pipelines feed an agent every five minutes without breaking? Could your semantic layer answer the same business question the same way three times in a row? Could your data governance survive an autonomous system making a decision your legal team has not approved?
If the answer to any of those is no, you are in the 93 percent. The good news is that the path out is well understood. Fix the floor before you let the agents run. Start at one, not at four. Allocate intelligence to the layer that actually needs it, which is almost never the one with the demos.
Seven percent of enterprises have figured this out. The other 93 percent will, eventually. The only question is how much of this year's AI budget they burn before they do.
Get in touch, to talk about your AI data readiness

More from Unwind Data

The Job Market Validated the Intelligence Allocation Stack
Major fintechs and tech companies are posting $300K+ roles that independently describe the same four-layer data-to-AI architecture. The Intelligence Allocation Stack is no longer a framework. It is a job description.
BI Migration Cost: What It Actually Takes to Move from Legacy Analytics
BI migration costs range from $50K to $500K+ depending on complexity. Learn what drives costs, which platforms companies migrate from, and how to calculate ROI.

IBM Just Spent $11 Billion to Prove AI Runs on Data, Not Models
IBM acquired Confluent for $11 billion. Not an AI model company. A data streaming platform. The smartest money in enterprise tech just validated the data-first thesis.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch