The Job Market Validated the Intelligence Allocation Stack
Major fintechs and tech companies are posting $300K+ roles that independently describe the same four-layer data-to-AI architecture. The Intelligence Allocation Stack is no longer a framework. It is a job description.

An $8 billion fintech just posted a $300K+ role. The job title: Director, Data & Knowledge Platform Engineering. The description reads like a framework I have been writing about for two years, built by someone who has never seen it.
Three layers. Data. Knowledge. Skills. Governed datasets feeding a semantic layer feeding agent-callable tools. That is not a job description. That is the Intelligence Allocation Stack written as a hiring spec.
And they are not alone.
The Pattern Hiding in Plain Sight
When one company posts a role like this, it is an outlier. When three do it in the same quarter, it is a pattern. When the World Economic Forum publishes data showing 72% of business leaders will prioritize data foundations and pipelines in 2026, it is a market shift.
Here is what I found when I started looking at director-level data platform roles posted in Q1 2026:
A major US sports league is hiring a Senior Director of AI Data Architecture. The role requires building "knowledge graphs, semantic layers, and context engineering that power AI systems and autonomous agents." Salary range sits north of $250K. The job description explicitly separates data infrastructure from the semantic layer from the AI application layer.
A leading AI research company is hiring a Director of Data Engineering and Agentic AI Automation for their finance division. The role bridges data platform engineering with autonomous agent deployment. Again: data foundation first, then orchestration, then agents.
An $8 billion fintech posted the role that caught my attention. Director, Data & Knowledge Platform Engineering, $300K to $330K. The description breaks their platform into three explicit tiers: Data (governed datasets, ingestion pipelines, warehousing), Knowledge (semantic layer, business logic, metric definitions), and Skills (agent-callable tools, orchestration, API integrations). They even used the phrase "semantic layer" unprompted.
Three companies. Three industries. The same architecture. None of them referencing each other or any shared framework. They arrived at the same conclusion independently.
Why This Matters More Than Another AI Announcement
Job descriptions are one of the most honest signals in the market. Companies do not pay $300K+ for roles they consider theoretical. They pay that when the gap between where they are and where they need to be is costing them real money.
When a fintech writes "Data, Knowledge, Skills" into a job spec, they are admitting something most vendors will not say publicly: AI agents without a data foundation are expensive toys. The intelligence has to be allocated to the right layer before the agents can run.
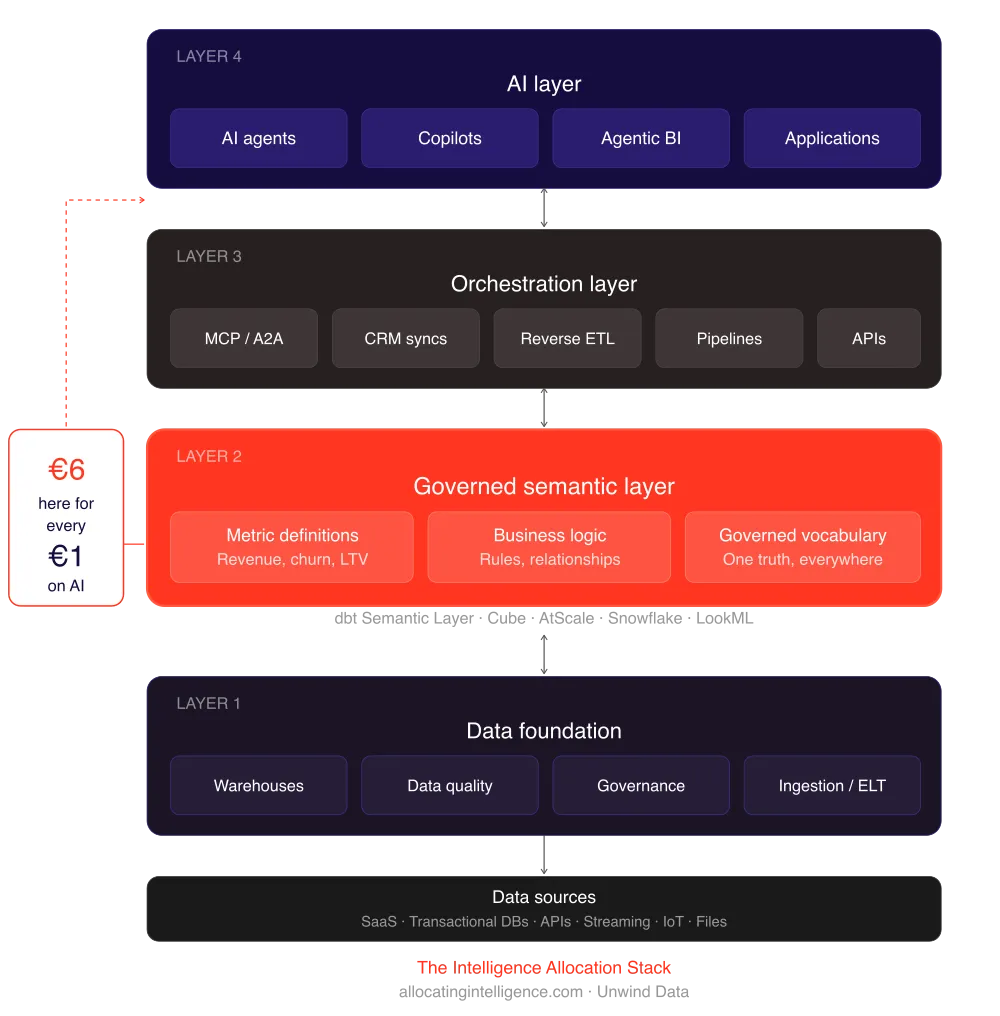
This is the core thesis behind the Intelligence Allocation Stack. For every dollar companies spend on AI, they should be spending six on the data architecture underneath it. Layer 1 (Data Foundation) feeds Layer 2 (Semantic Layer) feeds Layer 3 (Orchestration) feeds Layer 4 (AI). Skip a layer, and the agents hallucinate, the dashboards lie, and the $300K hire spends their first year cleaning up the mess instead of building the platform.
The Data Readiness Gap Is Still Massive
A March 2026 study by Cloudera and Harvard Business Review Analytic Services found that only 7% of enterprises say their data is completely ready for AI adoption. More than a quarter reported their data is "not very" or "not at all" ready. The top obstacles: siloed data and difficulty integrating sources (56%), lack of a clear data strategy (44%), and data quality issues (41%).
These numbers explain why companies are willing to pay $300K+ for someone who understands that you cannot deploy AI agents on top of ungoverned data. The role is not about building models. It is about building the floor the models stand on.
The World Economic Forum reported that fewer than one in five organizations have high maturity in any aspect of data readiness. Yet 72% of business leaders say they will prioritize data foundations and pipelines this year. The gap between intent and maturity is where these roles live.
Data, Knowledge, Skills: The New Platform Trinity
What struck me about the fintech role is the vocabulary. They did not call it "data engineering" or "analytics engineering" or "ML platform." They called it "Data & Knowledge Platform Engineering." That language choice matters.
Data is Layer 1 of the Intelligence Allocation Stack. Governed datasets, ingestion pipelines, data quality frameworks, the single source of truth. This is the foundation that 93% of enterprises still have not completed, according to the Cloudera/HBR research.
Knowledge is Layer 2. The semantic layer. Business logic translated into machine-readable definitions. Metric governance. The layer that ensures "revenue" means the same thing in every dashboard, every API call, every agent query. Tools like dbt Semantic Layer, LookML, and Omni live here. Without it, every AI agent invents its own definition of your KPIs.
Skills maps to Layers 3 and 4. Agent-callable tools, orchestration pipelines, API integrations, autonomous workflows. This is where AI agents actually do work. But they can only do useful work if Layers 1 and 2 are solid. An agent with skills but no knowledge is a confident liar. An agent with knowledge but no governed data is a well-spoken guesser.
The fintech understood this. They structured the role around all three layers, not just the flashy top one. That is rare. And that is why it pays $330K.
The Historical Pattern
I have seen this movie before. In 2018, every company suddenly needed a "Data Engineer" after years of asking Data Scientists to do infrastructure work. The job title existed before the widespread recognition, but the hiring surge told you where the market was heading.
In 2022, "Analytics Engineer" went from niche dbt community title to one of the fastest-growing roles in data. Companies realized they needed someone to own the transformation layer between raw data and business metrics.
In 2026, the pattern is repeating. The emerging role is the platform leader who owns the full stack from governed data through semantic layers to agent-ready APIs. The title varies. "Director, Data & Knowledge Platform Engineering." "Senior Director, AI Data Architecture." "Director, Data Engineering and Agentic AI." The titles differ. The architecture is identical.
Every cycle, the market rediscovers the same lesson: you cannot build intelligence on top of chaos. The only thing that changes is the price tag. Data Engineers in 2018 commanded $150K. Analytics Engineers in 2022 hit $200K. The data-to-AI platform leader in 2026 starts at $300K.
What This Means for Your Organization
If your company is hiring AI engineers before you have a governed data foundation, you are building Layer 4 on sand. The job market is telling you this in the most direct way possible: the companies with the biggest AI ambitions are investing first in Layers 1 and 2.
Three questions worth asking:
Do you have a semantic layer? Not a dashboard. Not a spreadsheet of metric definitions. A governed, machine-readable semantic layer that both humans and AI agents can query with consistent results. If the answer is no, your AI strategy has a $300K-shaped hole in it.
Can your agents access governed data? MCP, function calling, tool use. These protocols are only as good as the data they connect to. An AI agent with access to ungoverned data will confidently serve wrong answers at scale. That is worse than no agent at all.
Is your data architecture designed for machines, not just humans? The shift from dashboards to agents means your data layer needs to serve both. Governed datasets need to be queryable by LLMs, not just by analysts writing SQL. That is a data infrastructure problem, not an AI problem.
The Market Has Spoken
I have been writing about the Intelligence Allocation Stack for two years. The thesis has always been the same: start at Layer 1, not Layer 4. Fix the floor before you let the agents run. For every dollar on AI, six on data architecture.
I did not expect the validation to come in the form of job descriptions. But that is exactly what happened. When an $8 billion fintech independently arrives at the same four-layer architecture and is willing to pay $330K for someone to build it, the framework is no longer theoretical.
The Intelligence Allocation Stack is not a framework anymore. It is a job spec. And the market is hiring.
Systems beat individuals at scale. But only if you build the system in the right order.
More on Data Foundation
Get actionable insights on this topic — and more — straight to your inbox. No fluff.

More from Unwind Data

The dbt Fivetran Merger: What It Means for Your Data Stack
80-90% of Fivetran customers already used dbt. The merger formalized what most data stacks were already doing — but the implications for open source, the Iceberg bet, and the semantic layer are worth thinking through carefully.

Data Foundation for AI: What to Build Before the Model
Most AI projects fail before the model is ever the bottleneck. The real problem is the data foundation underneath. Here is what it takes to build one that actually supports production AI.

Enterprise AI Is Stalling on a Data Foundation Almost Nobody Has Built
Only 7% of enterprises say their data is completely ready for AI. The Cloudera and HBR 2026 report confirms what the 60% AI project failure rate has been screaming: the bottleneck is the data foundation, not the model.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch