Why AI Agents Hallucinate on Business Data: The Technical Breakdown
AI agents hallucinate on business data not because the model is bad, but because the data layer underneath it is non-deterministic. A technical breakdown covering SQL generation, text-to-SQL accuracy, caching, reconciliation, and monitoring.
Talk to an expertAsk an AI agent "what was our revenue last quarter?" on Monday. Write down the number. Ask the same question on Wednesday. Write down that number.
They will not match.
Ask a SQL analyst the same question twice. Run the query twice. The number is identical both times, because SQL is deterministic. Same query, same warehouse state, same result. Every time.
That gap — between what an agent returns and what a query returns, and between what the agent returns on Monday versus Wednesday — is not a model quality problem. It is an architecture problem. And until you understand exactly where it comes from, you will keep debugging symptoms instead of fixing the root cause.
This is the technical breakdown of why AI agents hallucinate on business data: what happens at the SQL generation layer, how caching creates phantom consistency, where reconciliation breaks down, and what monitoring actually needs to catch before a wrong number reaches a business decision.
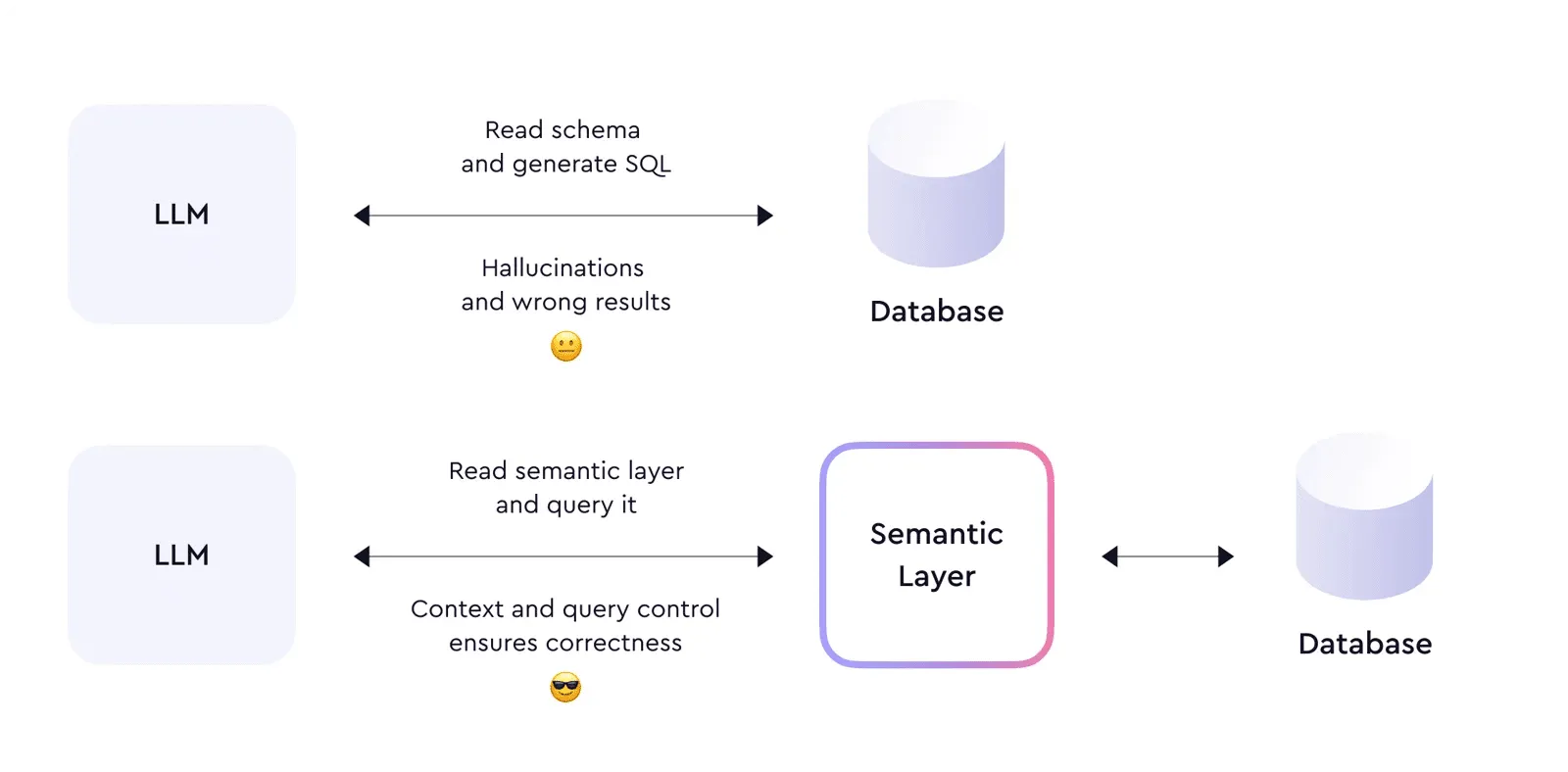
The determinism gap: why agents and SQL queries are not the same thing
SQL is deterministic. Given the same query string and the same warehouse state, a SQL engine returns the same result set every single time. No randomness. No interpretation. No variation based on time of day or conversational context. The output is a pure function of the input.
A large language model is non-deterministic by design. It generates output by sampling probability distributions over tokens. Temperature settings reduce this randomness but do not eliminate it. Even at temperature zero — the most constrained setting — many hosted models retain sources of variation through batching, floating-point non-determinism in GPU operations, and model versioning on the provider's side. The same prompt, submitted twice, can produce different SQL.
This is the core issue. When an AI agent answers a business data question, it is doing two things in sequence: generating SQL (non-deterministic) and then executing it (deterministic). The execution layer is reliable. The generation layer is not. And the generation layer is the one that encodes your business logic — which table to query, which columns to sum, which filters to apply, which joins to use.
Consider a simple example. A product manager asks: "What was last quarter's revenue?"
Run 1, the agent generates:
SELECT SUM(order_amount) FROM orders
WHERE order_date BETWEEN '2025-10-01' AND '2025-12-31'Run 2, the same agent generates:
SELECT SUM(total_price) FROM transactions
WHERE created_at >= '2025-10-01' AND created_at < '2026-01-01'Both queries execute successfully. Both return numbers. One uses order_amount (pre-tax), the other uses total_price (post-tax including shipping). One queries orders, the other transactions. The date filter logic differs in boundary handling. The results might differ by 8 to 15% in a real schema — enough to matter in a board presentation, enough to cause a finance reconciliation to fail.
Neither run produced an error. Both looked correct. That is exactly what makes this dangerous.
Text-to-SQL accuracy: the real numbers
The benchmarks used to sell text-to-SQL capabilities to enterprise buyers are almost universally measured on academic datasets. The industry-standard Spider benchmark uses databases with 5 to 20 tables, clean schemas, and well-named columns. On Spider, frontier models like GPT-4o achieve execution accuracy around 86%.
Enterprise schemas look nothing like Spider.
Research testing the same models on real enterprise databases — schemas with 1,000+ columns, non-intuitive abbreviations, implicit join relationships, and ambiguous metric definitions — found execution accuracy collapse to just 6%. Not a small drop. A 93% accuracy cliff.
In enterprise data warehouse environments with 500 or more tables, models hallucinate table references in over 60% of cases and column names in over 40% of cases when querying unfamiliar schemas without grounding constraints. One study found that without a semantic grounding layer, only 10 to 20% of AI-generated answers were accurate enough for business decisions.
The hallucination pattern is predictable. Models trained on public data have seen general SQL patterns but not your specific schema. They fill in gaps from probability distributions over what seems plausible. A column named rev might be interpreted as revenue. usr_cnt might be interpreted as user count. acq_dt might be guessed as acquisition date. Some of these guesses will be correct. Others will reference columns that do not exist, triggering silent errors — or worse, matching a different column with a similar name that measures something else entirely.
The silent failure is the one that causes real damage. A query that returns an error is visible. A query that returns a plausible but wrong number propagates into dashboards, reports, and AI-driven decisions without a flag. For more on how AI readiness connects to data architecture, see our guide on data architecture for AI agents.
What actually goes wrong in SQL generation
There are five specific failure modes that show up repeatedly in production text-to-SQL systems. Understanding them precisely changes how you approach the architecture.
Wrong table selection. The agent picks a table that sounds right but contains different data. In most enterprise warehouses, there are multiple tables that could plausibly answer a revenue question: orders, transactions, invoices, payments, revenue_daily. Without explicit guidance on which table is canonical for revenue, the model guesses based on naming conventions. The guess changes between runs.
Wrong column selection. Even with the right table, agents regularly select the wrong column. Pre-tax vs post-tax. Gross vs net. Invoice amount vs collected amount. These distinctions are meaningful to your finance team and invisible to the model. The column names in your schema do not reliably encode the distinction, and the model has no way to infer it without documentation.
Fan-out joins. This is the most technically damaging failure mode. If an agent joins orders to products and products has a many-to-many relationship with categories, each order row gets duplicated for every category. Revenue is then summed across the duplicated rows. The result is inflated by the average number of categories per product. The SQL executes cleanly. The number is wrong by a factor of 2x or 3x. This failure mode is particularly hard to catch without a validation layer that explicitly checks for row explosion on aggregations.
Inconsistent date boundary handling. Date ranges in SQL can be expressed multiple ways. BETWEEN '2025-10-01' AND '2025-12-31' is subtly different from >= '2025-10-01' AND < '2026-01-01' when timestamp data includes time components. Depending on which form the model generates, a query might include or exclude the final day of the quarter. This produces numbers that differ by a small but nonzero amount. When a business user asks the same question twice and gets slightly different results, they lose trust in the system.
Missing filters. Enterprise data typically contains rows that should be excluded from standard business metrics: cancelled orders, test accounts, internal transactions, refunded items. These exclusions are business logic. They are encoded in dashboards, in dbt models, sometimes in your documentation — but they are not in the raw table. An agent querying the raw table without those filters returns inflated numbers that do not match what Finance produces from the governed reporting layer.
Asking the same question twice: the caching trap
Here is a scenario that trips up every team that builds an AI data agent without thinking carefully about their caching layer.
Monday: a business user asks the agent "what was Q4 revenue?" The agent generates a SQL query, executes it, returns $4.2M, and caches the result against the natural language query hash.
Tuesday: your finance team closes the books and late invoices are posted. Q4 revenue is now $4.35M in the warehouse.
Wednesday: the same user asks "what was Q4 revenue?" The agent hits the cache, returns $4.2M, and the user makes a decision based on stale data. Finance runs the same query manually and gets $4.35M. A $150K discrepancy surfaces in a board meeting. Nobody can immediately explain why the AI told a different story than the finance report.
This is the cache result set problem. Caching query results for performance is a sound engineering decision. Caching them without a well-defined TTL and invalidation strategy against a live warehouse is a data governance failure.
The problem compounds when you add the non-determinism of the generation layer. The agent does not guarantee that the same natural language question maps to the same SQL query each time. If the cache key is the natural language string and the underlying SQL differs between runs, you get partial cache hits: some queries return cached results from one SQL variant, others execute fresh against a different SQL variant. The same user, asking the same question across two sessions, receives results from two different queries, neither of which is guaranteed to match the governed metric definition.
Cache result sets are appropriate in one scenario: when the query is fully deterministic, the cache key is the exact SQL string (not the natural language question), and the TTL is aligned with your warehouse refresh cadence. Anything short of this creates a silent consistency problem that is extremely difficult to debug after the fact.
Reconciliation: when three numbers appear for one metric
In organizations I have assessed, the standard breakdown looks like this. Ask the same revenue question to three systems: the AI agent, the BI dashboard, and the finance team's SQL query. You get three numbers. None of them match.
The divergence sources are predictable.
The AI agent generates SQL on the fly, without access to the business logic encoded in your governed reporting layer. It may query a different table, apply different filters, or use a different column. Its answer is whatever the probabilistic generation process produced that day.
The BI dashboard applies the business logic encoded in its modeling layer — whether that is LookML, a dbt semantic model, or a BI-native calculated field. But the dashboard may be running on a cached result from a scheduled refresh that has not yet captured today's data warehouse state.
The finance team's SQL query applies the canonical logic as they understand it, including any adjustments, manual exclusions, or fiscal calendar rules that are not encoded anywhere in the data infrastructure. Their number is authoritative but not automated.
Reconciliation in this environment is painful and recurring. Data teams spend significant time each week explaining to business users why the agent said one thing and the dashboard said another. The underlying cause is almost always the same: there is no single, governed definition of the metric that every consumer is forced to use. The agent can construct any query it wants. The BI tool uses its own logic. Finance has theirs. Three consumers, three definitions, three numbers. This is the data foundation problem described in detail in our complete semantic layer guide.
Query debugging: what "correct" actually means in production
Debugging text-to-SQL in production is different from debugging traditional application code. The failure mode is not an exception or a stack trace. It is a plausible-looking number that is wrong.
Effective debugging requires logging at three levels.
First, log the natural language question, the generated SQL, and the result set for every agent query. Without this, you cannot audit what the agent actually ran when a user reports a wrong number three days later. Most teams do not do this by default, because it feels like overhead. It is essential.
Second, implement a semantic validation layer that runs before query execution. This layer checks for specific anti-patterns: row-explosion risk from unconstrained joins on non-unique keys, aggregations without required filter conditions, queries against raw tables that should only be accessed through a governed view. These checks catch structural errors before they produce silently wrong results.
Third, implement result-level validation for high-stakes queries. After execution, compare the returned value against known bounds: the previous period's result, the value from the BI dashboard, or a threshold range defined by the data team. A variance above a configurable threshold should trigger a hold and a data team review rather than surfacing directly to the user.
The debugging workflow for a suspect agent answer follows a specific sequence. Pull the logged SQL from the query. Run it manually in your SQL client. Compare the result to the authoritative source. Identify which of the five failure modes produced the discrepancy. Then address it at the layer where it originated: schema documentation if the agent picked the wrong table, semantic layer if the metric definition was missing, validation rules if the filter was omitted.
Performance tuning: why agents make expensive warehouses more expensive
AI agents do not write performance-optimized SQL. They write SQL that answers the question. These are different objectives.
A human analyst writing a recurring query will add partition filters, use approximate aggregation functions where precision is not required, and avoid full table scans on large fact tables. An agent generating SQL on the fly has no awareness of your table's partition scheme, no knowledge of which columns are clustered, and no context about which queries are running concurrently. It will generate a full scan of a 500 billion row fact table to answer "how many orders shipped yesterday?" if the obvious syntax suggests that approach.
In Snowflake, BigQuery, and Databricks, warehouse costs are a direct function of data scanned. An agent that generates inefficient SQL for high-frequency questions can meaningfully increase compute costs without any human noticing until the bill arrives.
Performance tuning for AI agent SQL generation requires addressing this at three levels.
At the schema documentation level, include partition columns, clustering keys, and recommended filter patterns in the metadata that feeds the agent's context. If the agent knows that order_date is the partition column for the orders table and that queries without an order_date filter will cause full scans, it can include that filter by default.
At the query validation level, intercept queries that lack partition filters on large tables. Return an error to the agent with specific guidance — "this query will scan 500B rows, add a date filter" — and allow the agent to retry with the constraint. Most agents will correctly incorporate the feedback in the regenerated query.
At the caching level — and this is the correct use of caching — cache the SQL itself, not the result, for high-frequency queries that target governed metric definitions. If "total orders yesterday" always resolves to the same SQL via a governed semantic layer, cache that SQL string and reuse it. The query executes fresh each time against the current warehouse state, preserving correctness, but the expensive generation and validation cycle runs only once.
Monitoring: what a production AI data agent actually needs
Traditional BI monitoring tracks dashboard load times, query execution times, and data freshness. None of those metrics tell you whether an AI agent is producing correct answers.
Production monitoring for an AI data agent requires a different set of signals.
Answer consistency rate. Run a set of canonical questions on a daily schedule. Compare today's answers to yesterday's answers and to the governed values from your BI layer. Track the percentage that match within an acceptable variance threshold. Declining consistency rate is the earliest signal that something in the generation layer or the underlying data has shifted.
SQL variance by question. For each question in your canonical test set, track how often the generated SQL differs across runs. High variance on a specific question indicates the agent lacks sufficient grounding for that domain and is exploring probability space rather than resolving to a deterministic query. This is the precursor to a reconciliation failure.
Table and column hallucination rate. Log every instance where the agent generates a reference to a non-existent table or column. These errors are often swallowed silently if the agent has a retry mechanism — the agent retries with a different table guess, succeeds on the second attempt, and the user never knows the first attempt referenced a ghost. Tracking hallucination rate over time surfaces degradation in schema grounding that precedes visible quality problems.
Semantic coverage gaps. Track which questions the agent consistently cannot answer — questions where it falls back to an apology, produces high-variance SQL, or repeatedly generates invalid queries. These gaps map directly to missing metric definitions in your semantic layer. Each gap is a documentation task: define the metric, add it to the governed layer, and verify the agent resolves correctly.
Result staleness tracking. For any cached result set, track the delta between the cache timestamp and the current warehouse state timestamp. Surface this delta to the user alongside the result: "This answer reflects data as of 6 hours ago." This is not optional in environments where the warehouse refreshes on an intraday schedule. Hiding staleness is a data governance failure.
The fix is not a better model
Every failure mode described above — the non-deterministic SQL generation, the wrong table selection, the missing filters, the fan-out join, the cache staleness, the reconciliation gap — has a single architectural root cause. The agent has no governed definition of what the business metric means. It is navigating a raw schema using pattern matching and probability. It guesses well most of the time on simple schemas. It fails systematically on enterprise data.
The fix is not GPT-5 or a more powerful model. A more capable model will generate more syntactically sophisticated SQL. It will hallucinate less on table names. It will handle complex join logic better. But it still will not know that your company's definition of "revenue" excludes refunds processed after 30 days, that Q4 uses a fiscal calendar that ends on January 15, or that the orders table should always be filtered to status != 'TEST' before any aggregation.
Those definitions are not in any model's training data. They are in your organization's institutional knowledge, your finance team's heads, and — if you have built the right infrastructure — your semantic layer.
The semantic layer converts a non-deterministic problem into a deterministic one. Instead of the agent generating SQL from scratch, it resolves the natural language question to a governed metric definition. That definition specifies exactly which table, which column, which filters, which fiscal calendar adjustment, and which exclusion rules apply. The SQL is generated from the definition, not from a probabilistic guess at the schema. The same question asked twice resolves to the same definition and produces the same SQL. The result matches Finance's number because Finance's number was used to define the metric in the first place.
This is the pattern that produces 90%+ text-to-SQL accuracy in production enterprise environments. Semantic grounding, not model scale, is the variable that determines whether business users trust the agent's answers. For more on why MCP alone does not solve this, see why MCP without a semantic layer will fail. For how to structure the data foundation underneath your agents, see what an AI-ready data foundation actually requires.
What to actually build
If you are deploying an AI data agent right now, the minimum viable architecture for production reliability has five components.
A governed metric layer that defines every business metric as a named, versioned object with explicit SQL logic, filter conditions, and documentation. Every agent query resolves through this layer, not against the raw schema.
A schema documentation layer that provides the agent with table-level and column-level descriptions, partition information, relationship hints, and sensitivity labels. The goal is to eliminate the gap between what the model knows about SQL syntax and what it needs to know about your specific schema.
A pre-execution validation layer that intercepts generated SQL before warehouse execution and checks for structural anti-patterns: missing required filters, potential fan-out joins, references to unauthorized tables, and absence of partition columns on large tables.
A query audit log that captures every natural language question, the generated SQL, the execution timestamp, and the result set. Non-negotiable for debugging, governance, and reconciliation.
A result validation layer for high-stakes queries that compares returned values against known-good references before surfacing to the user. Not every query needs this. Revenue, headcount, and financial metrics do.
None of these components require a newer or bigger model. They require the data foundation to be in place before the agent is deployed. 88% of companies are using AI in at least one business function. Only 39% see measurable impact. The companies in that 39% are not running better models. They are running AI on governed data with the right architectural controls underneath. The hallucination problem is solvable. The solution is the data layer, not the model layer.
For every dollar companies spend on AI, six should go to the data architecture underneath it. The determinism gap is exactly why.
Stay current on AI in data
Hands-on insights on deploying AI agents, LLMs, and automation in real data workflows.
Unwind Data
Speak with a data expert
We've helped scale-ups and enterprises move faster on exactly this kind of work — without the trial and error. Strategy, architecture, and hands-on delivery.
Schedule a consultation