
75% of companies plan to deploy AI agents by the end of 2026. That number comes from Deloitte's latest State of AI in the Enterprise report. It sounds like progress.
But here is the number nobody is talking about. Formal AI governance policies dropped from 45% to 37% over the same period. Companies are deploying faster and governing less. That is not a strategy. That is a countdown.
The Governance Gap Is Not an AI Problem
When most people hear "AI agent governance," they think about guardrails on the model. Prompt injection. Hallucination filters. Output validation. Those matter, but they are symptoms. The actual disease is deeper.
AI agents require access to high-quality, governed data to function. They need to know which metric definitions are authoritative. They need lineage to trace where a number came from. They need semantics to understand what a field means in context, not just what it is called in a table.
Without that foundation, you do not have an ungoverned AI agent. You have an ungovernable one. There is a difference. The first implies you chose not to add controls. The second means you cannot add them even if you wanted to, because the data layer underneath does not support it.
80% of Fortune 500 Companies Use Active AI Agents
Microsoft reported in February 2026 that 80% of Fortune 500 companies now use active AI agents. That is an extraordinary adoption curve. But the same research landscape shows that only 24.4% of organizations have full visibility into which AI agents are communicating with each other. More than half of all agents run without any security oversight or logging.
Think about what that means. Companies have deployed autonomous systems that can read data, make decisions, and take actions. And most of them have no idea what those systems are actually doing or what data they are pulling from.
This is what happens when you start at Layer 4 and skip Layers 1 through 3.
The Intelligence Allocation Problem
I have been writing about what I call the Intelligence Allocation Stack for the past two years. The idea is simple. Every enterprise has four layers to get right before AI works at scale.
Layer 1 is the data foundation. Data governance, data quality, ingestion pipelines, warehousing, a single source of truth. Layer 2 is the semantic layer. Business logic translated for machines, metric definitions, governed vocabulary. Layer 3 is the orchestration layer. Data pipelines, CRM syncs, reverse ETL, workflow automation. Layer 4 is the AI layer. Agents, conversational AI, autonomous systems, predictive models.
For every dollar companies spend on AI, they should be spending six on the data architecture underneath it. That ratio sounds aggressive until you see what happens when companies invert it.
Gartner still projects that 60% of AI projects will be abandoned because the data is not AI-ready. That prediction has held steady for two years now. The failure rate is not improving because companies keep trying to solve a Layer 1 problem with Layer 4 spending.
We Have Seen This Pattern Before
In 2018, every company was hiring data scientists. They were going to unlock the value hidden in company data. What actually happened is that those data scientists spent 80% of their time cleaning data and building pipelines, because the data infrastructure was not there. The talent was Layer 4. The bottleneck was Layer 1.
In 2022, the same pattern repeated with dashboards and BI tools. Companies bought Looker, Tableau, Power BI. They expected instant insight. What they got was conflicting numbers, because nobody had agreed on metric definitions or built a semantic layer. The tooling was Layer 3. The bottleneck was Layer 2.
Now in 2026, AI agents are the new promise. Deploy an agent. Automate the workflow. Cut the headcount. But the agents are pulling from the same ungoverned, inconsistent, poorly documented data that confused the data scientists and broke the dashboards. The intelligence is at Layer 4. The bottleneck is still Layer 1.
The pattern does not change because the technology changes. It changes when the data foundation changes.
What "AI-Ready Data Governance" Actually Requires
The 2026 enforcement cycle of the EU AI Act is now live. High-risk AI systems are subject to transparency and oversight requirements that most companies cannot meet with their current data infrastructure. ISO/IEC 42001 adoption is accelerating, and organizations are standing up model inventories, risk assessments, and monitoring pipelines.
But here is the part that keeps getting missed. You cannot govern an AI agent if you cannot govern the data it consumes. Agent governance is downstream of data governance. Always.
What does AI-ready data governance look like in practice? It starts with three non-negotiable capabilities.
First, semantic clarity. Every dataset that an AI agent can access needs machine-readable business logic. Not just column names and data types. The agent needs to know that "revenue" means net revenue after returns, calculated using the formula in the finance team's approved metric definition. That is the semantic layer doing its job.
Second, complete lineage. When an AI agent surfaces a number in a report or makes a decision based on a data point, you need to trace that number back to its source. Which pipeline ingested it. Which transformations were applied. Which business rules were used. Without lineage, you cannot audit. Without audit, you cannot govern.
Third, access controls that understand context. Traditional role-based access is not enough for AI agents. An agent operating on behalf of a marketing analyst should not have the same data access as an agent operating on behalf of the CFO. Data governance needs to extend to agent-level permissions, and that requires a data infrastructure that supports fine-grained, context-aware access policies.
The Companies Getting It Right
The companies I work with that are succeeding with AI agents share one characteristic. They invested in data infrastructure before they invested in AI. They built the semantic layer. They documented the business logic. They established a single source of truth before they let an agent anywhere near it.
IDC research shows that companies with mature data governance see 24% higher revenue from AI initiatives. That number is not a coincidence. It is causation. When the foundation is solid, everything built on top performs better.
Meta published a case study this month showing how they used 50 specialized AI agents to map tribal knowledge across 4,100 files in their data pipelines. The result was a 40% reduction in AI agent errors. But notice what they did. They did not just deploy smarter agents. They invested in documenting and structuring the data layer first. The agents got better because the foundation got better.
Stop Starting at Layer 4
If your organization is in the 75% planning to deploy AI agents this year, ask one question before you start. Can you explain, in machine-readable terms, what your core business metrics mean and where the numbers come from?
If the answer is no, you are not ready for AI agents. You are ready for a data governance initiative. And that is not a consolation prize. That is the highest-ROI investment you can make right now.
88% of companies use AI in some form. Only 39% see measurable impact. The 49-point gap between adoption and impact is not a technology gap. It is a data architecture gap. And it will not close by adding more agents to an ungoverned data estate.
Systems beat individuals at scale. But only if the system starts with the right foundation.
Stay current on AI in data
Hands-on insights on deploying AI agents, LLMs, and automation in real data workflows.

More from Unwind Data
Snowflake Cortex Sense, CoCo and CoWork Explained
Snowflake shipped Cortex Sense, CoCo Desktop, and CoWork at Summit 26. Cortex Sense is the context runtime that sits between the model and the data. Here is what each product does and why the three form a coherent agentic stack.
Google's Agentic BI Era With Looker: Why I Think They're Making the Right Bet
Google announced the agentic BI era with Looker at Next '26: BI agents, a native MCP server, Gemini-powered LookML, and the Knowledge Catalog. Here is why I think this is the right move — and the one thing that still determines whether it works.
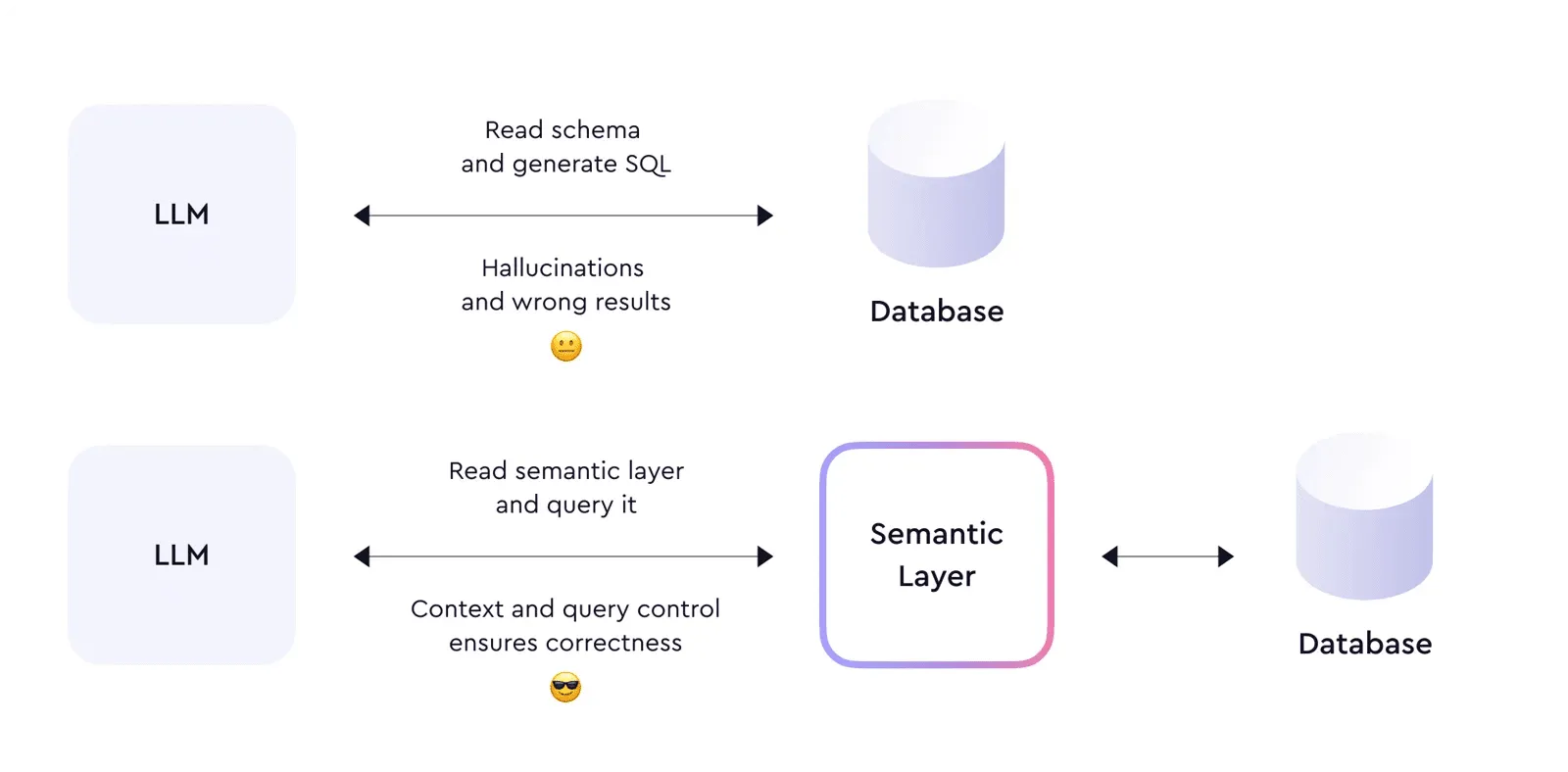
Why AI Agents Hallucinate on Business Data: The Technical Breakdown
AI agents hallucinate on business data not because the model is bad, but because the data layer underneath it is non-deterministic. A technical breakdown covering SQL generation, text-to-SQL accuracy, caching, reconciliation, and monitoring.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch