Google's Agentic BI Era With Looker: Why I Think They're Making the Right Bet
Google announced the agentic BI era with Looker at Next '26: BI agents, a native MCP server, Gemini-powered LookML, and the Knowledge Catalog. Here is why I think this is the right move — and the one thing that still determines whether it works.
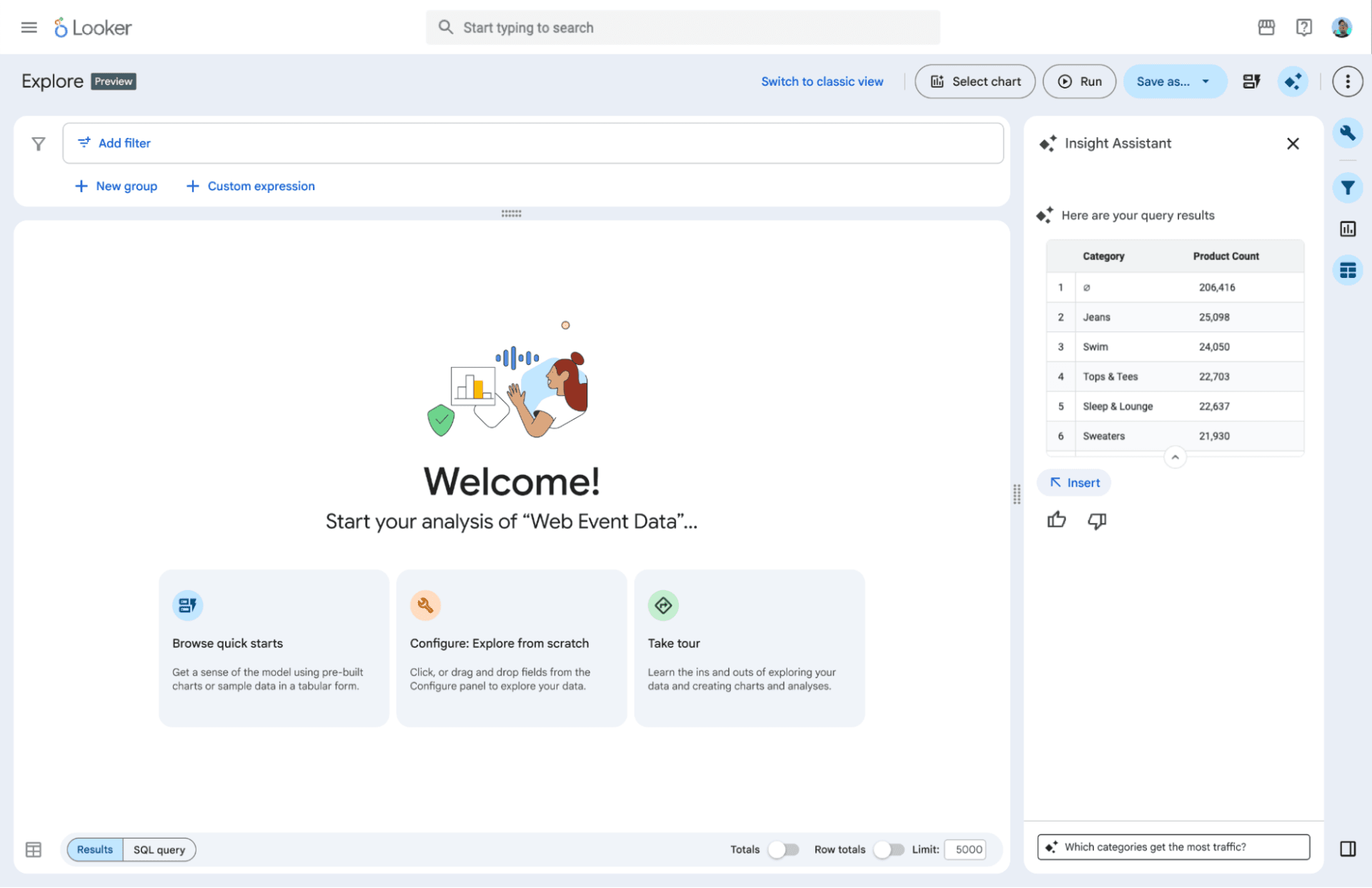
At Google Cloud Next '26 this week, Google announced what they are calling the agentic BI era with Looker. New agents, a native MCP server, Gemini-powered LookML authoring, self-service Explores that blend personal data with governed enterprise metrics, and a tighter integration with the Knowledge Catalog — a new context engine built on top of Dataplex that is positioned as the grounding layer for every AI agent in the Google Cloud ecosystem.
My reaction is straightforward: this is the right move, announced at the right time, and it confirms something I have been arguing for the past two years.
The semantic layer is not a BI feature. It is the infrastructure that determines whether AI agents produce reliable outputs or confident noise. Google just officially reorganized Looker around that thesis.
What Google Actually Announced
The headline is Looker BI Agents — agents that do not just answer questions but trigger downstream business actions, grounded in the Looker semantic layer and the organization's existing governance framework. Dashboard Agents bring conversational capabilities directly into dashboards. An Agentic Workflows feature monitors critical metrics for irregularities and surfaces "what's next" recommendations before problems reach the bottom line. And Embedded Conversational Experiences, now generally available, lets organizations embed these agents into their own applications and internal tools via UI or API.
On the developer side, a VS Code extension with a LookML AI Agent that generates production-ready LookML from natural language descriptions. CI/CD for Looker is now generally available, automating SQL validation and content testing before changes reach production. And a native managed MCP server — Looker's own Model Context Protocol server — that makes the entire LookML semantic layer queryable by any AI agent that speaks MCP.
Self-service Explores reached general availability too. The feature lets business users blend personal data from CSV and Excel files with governed enterprise data, with Looker handling the LookML code behind the scenes. As one CTO quoted in the announcement put it: the flexibility of Excel with the governance of an enterprise platform.
And quietly, tucked into the trusted platform section: Knowledge Catalog integration, which connects Looker to a broader initiative I will come back to at the end.
Why I Think This Is a Good Move
In 2022, I watched organizations buy dashboard tools before they had a semantic layer. The dashboards disagreed with each other, the numbers were never trusted, and nobody made decisions from them. In 2026, those same organizations are deploying AI agents before they have governed data foundations. The agents make decisions on top of metrics they cannot explain, definitions they cannot enforce, and systems that were never designed to be queried autonomously.
Google is doing something important here. They are not just adding AI features to a BI tool. They are repositioning Looker's semantic layer — LookML — as the foundational layer that makes AI agents trustworthy. That is the correct architectural bet.
The Intelligence Allocation Stack I have written about describes four layers that must be built in order: data foundation, semantic layer, orchestration, AI. Most organizations skip straight to layer four. The result is always the same: the agents collapse into the gaps underneath them. Google's agentic BI announcement is essentially a product strategy built around the same argument — that agents without a governed semantic layer underneath them will fail in production, and that LookML is the governed semantic layer Google is betting on.
The MCP server announcement matters most to me. We wrote earlier this year about why MCP without a semantic layer will fail. The argument was simple: MCP is plumbing. It connects AI agents to data sources via a standard protocol. But the semantic layer is the brain — the governed definitions, the business logic, the metric calculations — that determines whether the agent returns a reliable answer or a probabilistic guess dressed up as a fact. A native MCP server for Looker means any AI agent that speaks MCP can now query the LookML semantic layer directly. The protocol and the brain are finally packaged together.
Self-service Explores solving the "Excel vs governance" problem is also significant, and underappreciated in most coverage of this announcement. The tension between analyst freedom and data governance is one of the oldest problems in enterprise BI. Every team I have worked with faces the same version of it: finance wants to do ad-hoc analysis that goes beyond the governed data model, so they download to Excel, apply their own logic, and produce a number that nobody else can reproduce or audit. Self-service Explores closes that loop. The ad-hoc analysis happens inside the governed environment. The underlying business logic is still accurate even when the exploration is free-form. That is not a minor feature. For organizations that spend engineering time constantly reconciling what finance did in a spreadsheet against what the BI tool says, this changes a real workflow.
The Thing That Has Not Changed
All of this is genuinely exciting, and I want to be honest about the constraint that does not go away.
Every feature announced at Next '26 works on top of a well-maintained LookML model. The agents are grounded in the LookML semantic layer. The MCP server exposes LookML definitions. The Knowledge Catalog aggregates LookML into its context engine. Self-service Explores extend a governed LookML model with personal data.
If your LookML model is outdated, under-documented, or maintained by one person who joined two years ago and left last quarter, none of these announcements will save you. Garbage in, confident agent out. The same principle applies here that applies to every AI implementation: the quality of the underlying data foundation determines the quality of the outputs above it.
Google has built a compelling agentic layer on top of Looker. The organizations that will get value from it immediately are the ones that have already invested in clean, well-governed LookML. The organizations that skipped that investment will get impressive demos and unreliable production results.
The sequence is always the same. Fix the semantic layer first. The agents work when you do.
This is also worth noting for organizations evaluating Sigma as a Looker alternative right now. We covered the Sigma vs Looker decision recently. Sigma's architectural bet is that the semantic layer should live in the warehouse, not the BI tool. Google's bet is the opposite: LookML as a durable, BI-native semantic layer that becomes the grounding for everything above it, including AI agents. Both positions are defensible. But if your organization's AI roadmap runs through Google Cloud and Gemini, the case for LookML just got significantly stronger.
The Knowledge Catalog: The Bigger Initiative Worth Watching
Tucked into the Looker announcement is an integration with something called the Knowledge Catalog, announced separately at Next '26 as an evolution of Dataplex. This is the broader initiative, and it is worth understanding because it is Google's answer to a question that every enterprise AI deployment eventually surfaces: where does an AI agent get the context it needs to understand your business?
Traditional data catalogs were built as manual inventories for technical users. They answered the question of what data exists and where it lives. The Knowledge Catalog is designed to answer a different question: what does the data mean, how does it relate to everything else, and how can an AI agent use it reliably without guessing at business definitions it was never trained on?
Google is evolving Dataplex into what they describe as a "universal context engine" built on three pillars. Aggregation: pulling metadata from across the entire data estate, including BigQuery, Looker, third-party catalogs like Atlan and Collibra, and enterprise applications including SAP, Salesforce, ServiceNow, and Workday. Enrichment: continuous, AI-powered generation of descriptions, relationships, and verified SQL patterns that keep the catalog current without requiring manual curation. And search: high-precision semantic retrieval, access-control-aware, built on Google's own search infrastructure so agents can retrieve the right context at the latency production use cases require.
The Looker integration connects directly to this. LookML definitions — metrics, dimensions, relationships, business logic — are aggregated into the Knowledge Catalog, making them available as context to any AI agent operating in the Google Cloud ecosystem. Bloomberg Media is already using this in production, according to the announcement, grounding their internal data access agent in unified enterprise metadata via the Knowledge Catalog.
What interests me most about the Knowledge Catalog is the LookML Agent within it: a feature that reads strategy documents and automatically generates business-ready LookML semantics from them. This is Google's attempt to solve the cold start problem — the fact that building a well-governed LookML model from scratch is expensive, requires specialist knowledge, and takes months. If the LookML Agent can accelerate that process meaningfully, it removes one of the main objections organizations have to investing in LookML in the first place.
The Knowledge Catalog is early. Most of the capabilities announced are in preview, not generally available. And the value proposition is only realized when the underlying metadata is clean enough to aggregate, which requires the same data foundation work that every other AI initiative requires. But the architecture is right. A universal context engine that aggregates semantic definitions from across the enterprise, keeps them current automatically, and serves them to AI agents at query time is exactly what the market needs. Google has the search infrastructure, the LLM capability, and the data platform scale to build it credibly.
What This Means for the Market
We wrote about Google's Looker and Data Studio rebrand when it happened. At the time, the thesis was that Google was clarifying the product positioning: Looker for governed enterprise BI, Data Studio for lighter consumer-grade reporting. The agentic BI announcement at Next '26 extends that strategy to its logical conclusion. Looker is not a BI tool competing with Tableau and Power BI on visualization capabilities. It is the semantic layer for Google's agentic data cloud.
That is a significantly more defensible position. Visualization is a commodity. Every major BI tool has acceptable charts. Governed semantic infrastructure for AI agents is not a commodity. It requires deep integration between the definition layer, the governance model, the consumption interface, and the AI runtime. Google has now connected all four of those things inside a single product ecosystem.
For organizations evaluating enterprise BI in 2026, the question is no longer "which tool makes the best dashboards." It is "which architecture makes our AI agents trustworthy." Google's answer is Looker plus LookML plus the Knowledge Catalog. Whether that answer fits your organization depends on how committed you are to the Google Cloud ecosystem. But the bet itself is sound.
The semantic layer always was the point. It took the AI agent era to make everyone else see it too.
Stay current on AI in data
Hands-on insights on deploying AI agents, LLMs, and automation in real data workflows.

More from Unwind Data
Snowflake Cortex Sense, CoCo and CoWork Explained
Snowflake shipped Cortex Sense, CoCo Desktop, and CoWork at Summit 26. Cortex Sense is the context runtime that sits between the model and the data. Here is what each product does and why the three form a coherent agentic stack.
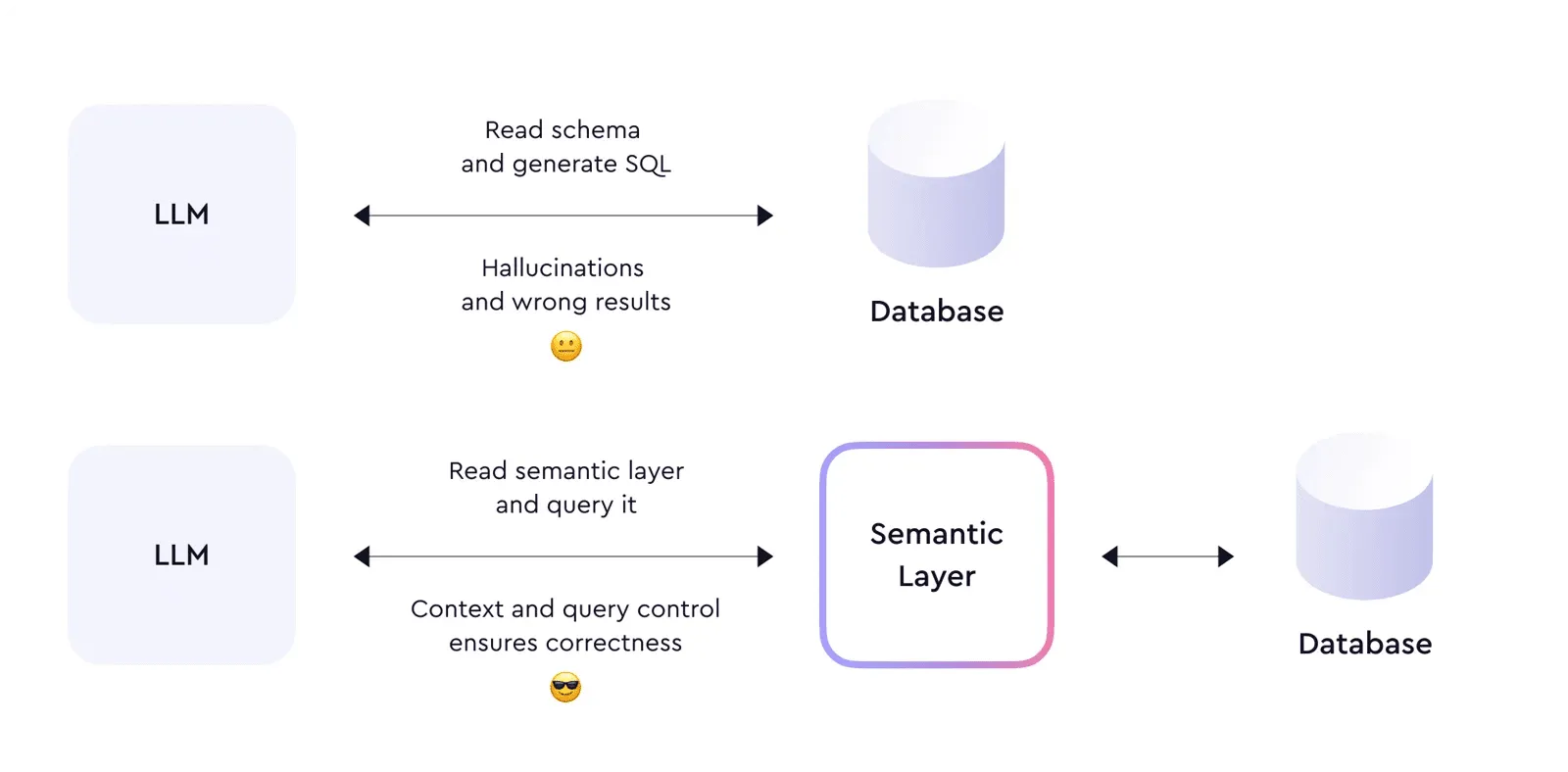
Why AI Agents Hallucinate on Business Data: The Technical Breakdown
AI agents hallucinate on business data not because the model is bad, but because the data layer underneath it is non-deterministic. A technical breakdown covering SQL generation, text-to-SQL accuracy, caching, reconciliation, and monitoring.

Why AI Agent Governance Is Getting Worse, Not Better
75% of companies plan to deploy AI agents by end of 2026. Meanwhile, formal governance policies dropped from 45% to 37%. The problem is not the agents. It is what is underneath them.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch