93% of Enterprises Are Building AI on Sand. Here's What the Data Actually Says.
New research from Harvard Business Review and Cloudera reveals only 7% of enterprises say their data is completely ready for AI. Here's what the numbers mean for your data strategy and AI investment.

Harvard Business Review and Cloudera published a joint study this month. They surveyed hundreds of enterprise leaders across industries. The finding that stopped me: only 7% of enterprises say their data is completely ready for AI.
That means 93% of companies building AI strategies right now are doing it on a foundation they know is broken. True AI data readiness — the ability to reliably ingest, govern, and serve data to AI systems — is absent in almost every enterprise operating today.
This was not a single outlier report. The same week, Deloitte published their State of AI 2026. Cockroach Labs released their annual infrastructure findings. Three research teams. Three methodologies. One conclusion.
What the Data Actually Says
Start with the Cloudera and Harvard Business Review finding: 7% of enterprises report their data is completely AI-ready. That is not a rounding error. That is a structural problem at the core of enterprise AI strategy.
Deloitte's State of AI 2026 adds granularity to the same story. Data governance readiness sits at 30%. Data management readiness at 40%. Talent readiness falls to just 20%. The technical infrastructure score is the highest of the group at 43%, which means companies have bought the tools. They just have not built the data foundation beneath them.
The Cockroach Labs 2026 AI Infrastructure Report adds a timeline to the risk: 83% of business leaders believe AI-driven demand will cause their data infrastructure to fail within the next 24 months. One in three expects that failure within 11 months. And 98% of companies say one hour of AI-related downtime would cost at least $10,000, with nearly two-thirds estimating losses above $100,000 per hour.
When you put these three reports side by side, the picture is clear. Companies are not failing at AI because the models are bad. They are failing because the data architecture underneath those models was never designed for what AI requires. AI data readiness is not a checkbox — it is a multi-year structural investment.
I Have Seen This Pattern Since 2018
When I co-founded DataBright in 2018, AI was already being sold as the answer to every business problem. The companies we worked with across fintech, e-commerce, and SaaS were hiring data scientists before they had a single clean data pipeline. They were running predictive models on top of spreadsheets duct-taped to CRMs. They were allocating their intelligence budget to Layer 4 while Layers 1 through 3 did not exist.
In 2019, I wrote about the Data Engineer hiring wave coming to clean up the mess. That article described the same structural problem: companies building the intelligence layer before the data foundation was solid. The teams we brought in were not building new capabilities. They were fixing the floor so the building would not collapse.
Seven years later, the terminology has changed. The budgets are bigger. The tools are more powerful. The pattern is identical.
This is not a coincidence. It is what happens when organisations optimise for visible progress over structural integrity. Deploying an AI agent is visible. Rebuilding your data governance framework is not. One gets budget approval in a single slide. The other gets deferred to next quarter, indefinitely.
The Intelligence Allocation Stack
The framework I use to diagnose where companies are stuck is called the Intelligence Allocation Stack. It has four layers, and the order matters more than the technology choices at any given layer. Understanding this stack is foundational to understanding what real AI data readiness looks like in practice.
Layer 1: Data Foundation. This is data governance, data quality, ingestion pipelines, warehousing, and the single source of truth. Without this layer, everything built on top produces unreliable outputs. No AI model can compensate for ungoverned data at the source. This is where only 30% of enterprises have adequate readiness, according to Deloitte.
Layer 2: Semantic Layer. This is where business logic gets translated into machine-readable definitions. Metric definitions. Governed vocabularies. Consistent terminology so that when an AI agent asks 'what is revenue,' every system returns the same answer. Tools like dbt Semantic Layer, Looker, and Omni sit at this layer. Most companies skip it entirely.
Layer 3: Orchestration Layer. Data pipelines, CRM syncs, reverse ETL, API integrations, real-time event processing. This is the connective tissue that keeps data moving reliably between systems. Without it, AI agents are working with stale snapshots and incomplete context.
Layer 4: AI Layer. AI agents, conversational interfaces, autonomous systems, predictive models. This is where most companies start their AI strategy. This is also where the 7% statistic originates. The companies in that 7% did not get there by deploying better models. They got there by building Layers 1 through 3 first — they invested in AI data readiness before they invested in AI itself.
The Failure Mode Nobody Wants to Admit
When AI projects fail, the post-mortem almost always points to data. But the framing is usually wrong. Organisations say 'our data quality was not good enough' as if it is a one-time remediation task. The real problem is that data quality was never governed systematically, because the data governance layer was never properly built.
AI agents that hallucinate in production are almost never broken because of the model. They hallucinate because the semantic layer was never built and the agent has no consistent definition of the business concepts it is reasoning about. Ask it about 'active customers' and it returns a different number depending on which pipeline it queries.
Predictions that cannot be trusted come from data pipelines that were built for reporting, not for the real-time data architecture that autonomous AI decisions require. The engineering team built pipelines for dashboards. Nobody rebuilt them for agents.
Gartner's prediction that 60% of AI projects will be abandoned due to poor data readiness is materialising right now. What the 2026 reports add to that forecast is urgency and financial consequence. Leaders know infrastructure failure is coming. 83% of them say so. Yet the investment allocation continues to flow disproportionately into Layer 4.
What Poor AI Data Readiness Costs You
It is worth naming the cost explicitly. Poor AI data readiness does not just mean your AI project underperforms. It means your AI project actively erodes trust. When an AI-powered dashboard returns different revenue figures depending on which filter a sales rep applies, confidence in the entire analytics stack drops. When an AI agent sends a personalised email based on stale customer data, churn risk increases. When a compliance-critical AI decision cannot be audited back to a clean data source, the legal exposure is real. Learn more about building a data governance foundation that AI systems can rely on.
What Companies Getting Real ROI Are Doing Differently
IDC research finds that companies with mature data governance see 24% higher revenue from AI than those without. That number is not a coincidence. It is the compounded result of building from the bottom up over time.
The teams getting real, measurable ROI from AI share a common trait: they treated data infrastructure as a prerequisite, not a parallel workstream. They fixed data quality before deploying AI agents. They built the semantic layer before connecting a conversational interface to their data warehouse. They established data governance before letting autonomous systems act on business-critical data. In short, they prioritised AI data readiness over AI deployment speed.
In fintech, data governance is the difference between a compliance failure and a clean audit trail. In e-commerce, a single source of truth for customer data is the difference between personalisation that converts and recommendations that confuse. In SaaS, orchestration layer reliability separates AI features that retain customers from those that generate support tickets.
Systems beat individuals at scale. A well-governed data architecture compounds over time. The companies that built from Layer 1 in 2021 and 2022 are the ones extracting real value from AI in 2026. The companies that started at Layer 4 are the ones represented in the 93%. Read our full breakdown of the Intelligence Allocation Stack to see where your organisation sits.
For Every Dollar Spent on AI, Six Should Go to Data Architecture
This is the thesis Unwind Data was built around. It is not a contrarian position for its own sake. It is what a decade of building data infrastructure across dozens of companies and four verticals has consistently shown to be true.
The 2026 research confirms it with numbers that are hard to ignore. 93% of enterprises do not have AI-ready data. Only 30% have adequate data governance. 83% are heading toward infrastructure failure within two years. Only 15% of organisations have mature data governance at all, according to DATAVERSITY.
AI data readiness is not a nice-to-have. It is the prerequisite that determines whether your AI investment returns ten times what you spent or ends up as a case study in wasted budget. The companies achieving the former built their data foundation first. The companies experiencing the latter skipped it.
The question is no longer whether your data foundation needs investment. That question has been answered. The question is whether your organisation starts building it now, before the AI infrastructure failure, or after it.
Start at Layer 1. Not Layer 4.
More data strategy insights like this
Join data and operations leaders getting Unwind's biweekly roundup on turning data into decisions.

More from Unwind Data

BI Migration Approach: What Actually Works and What Breaks
Most BI migrations fail because teams migrate dashboards instead of fixing the logic underneath them. Here is a honest account of what works, what breaks, and why the semantic layer is where every migration should start.
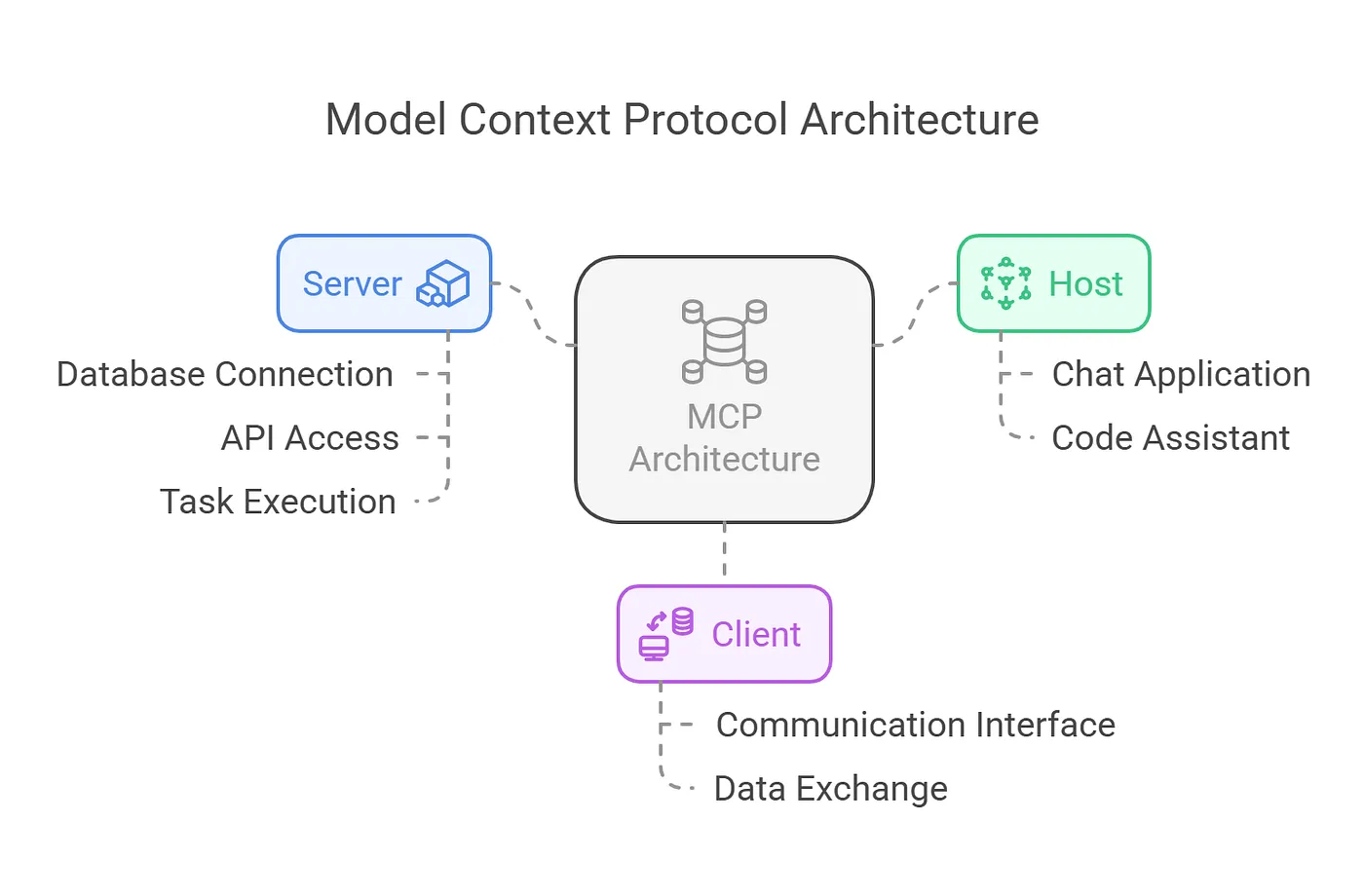
MCP Fails Without a Semantic Layer (+ Implementation Patterns)
Gartner warns 60% of agentic analytics projects relying solely on MCP will fail by 2028. Here are the three MCP semantic layer integration patterns that separate production deployments from expensive proof-of-concept pilots.

90% of Companies Are Weakening AI Agent Governance to Ship Faster. Here's Why That Backfires.
90% of organizations pressure security teams to loosen AI controls. Meanwhile, companies with AI governance ship 12x more projects to production. The fix isn't speed. It's data architecture.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch