Semantic Layer vs Text to SQL: The Architecture Decision
Text-to-SQL accuracy nearly doubled between 2023 and 2026. The semantic layer still wins on determinism. But the real question isn't which benchmark wins — it's an architecture decision about where your business logic lives.
Talk to an expertThe benchmark that reignited a debate worth having
The semantic layer vs text to sql question now has 2026 numbers behind it. Earlier this year, dbt Labs reran a benchmark they first published in 2023. The question was simple: when you give an LLM access to your data, is it better to let it write SQL directly, or route it through a structured semantic layer?
In 2023, the semantic layer won by a wide margin. Text-to-SQL accuracy sat at 32.7% on the full question set. Not great. The semantic layer, for questions within its scope, returned correct results nearly every time.
Three years later, the gap has narrowed significantly. Text-to-SQL accuracy nearly doubled, from 32.7% to 64.5% on the full question set. Models have gotten dramatically better at writing SQL. For questions within the Semantic Layer's scope, both models now return correct results 100% of the time.
This is the debate in 2026 — and the data is genuinely interesting. But the framing of "which one wins" misses the actual decision you are making. This is not a technology race. It is an architecture decision about where you encode your business logic and how much you trust your data infrastructure to hold it.
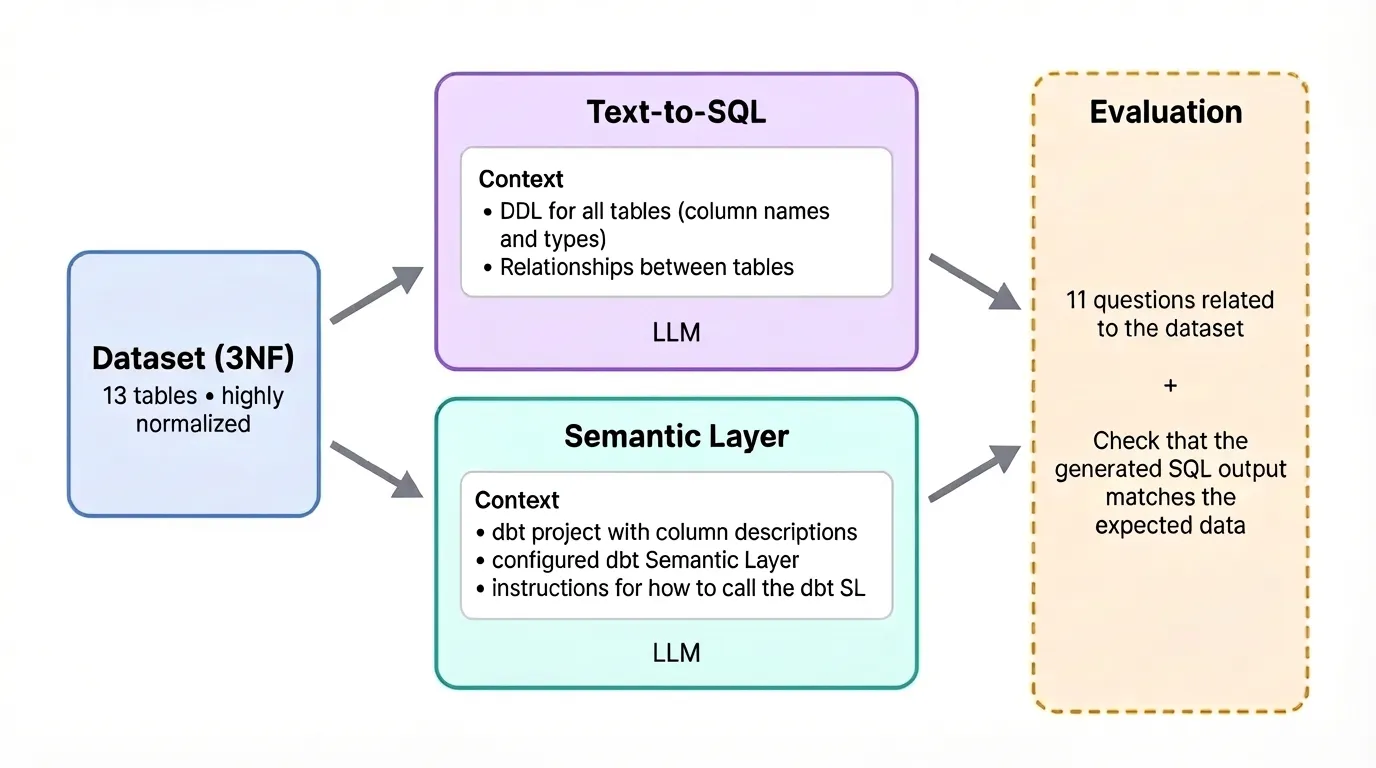
What the 2026 numbers actually tell you
The dbt benchmark used GPT-4 from November 2023 and compared it against GPT-5.3 Codex and Sonnet 4.6 from early 2026. Same 11 questions, run 20 times each.
The recommendation from dbt's own benchmark: Text-to-SQL for ad hoc analyses and smaller datasets. Semantic Layer for enterprise use where accuracy is critical and datasets are large, complex, or messy.
That is a useful framing, but it is worth reading between the lines. The benchmark was run on a controlled dataset by a vendor that sells a semantic layer product. That does not make the results wrong. But it does mean you should pressure-test the methodology before making architectural decisions based on it.
The more interesting question is not what the number is. It is what drives the gap.
For ad hoc exploration — one-off questions, data discovery, prototyping — dbt recommends checking if the Semantic Layer can answer first, and if not, falling back to text-to-SQL with as much schema context as possible. That practical recommendation reveals the real architecture: the two approaches are not mutually exclusive. They handle different parts of the same problem.
The counter-argument and where it holds
Not everyone agrees the semantic layer is necessary for AI-accurate querying. MotherDuck published a notable counter-argument: running 500 text-to-SQL questions against three frontier LLMs with zero context beyond the schema, achieving 95% accuracy — and concluding that if your data model is clean and your context is targeted, a formal semantic layer adds almost nothing for AI use cases.
This result is real. But the asterisk matters enormously.
The 95% number was measured on a clean, controlled dataset using the BIRD benchmark. BIRD uses strict execution accuracy: it compares result sets byte-for-byte, penalizing queries that return extra helpful columns, use DISTINCT differently, or round numbers to a different precision — none of which are wrong answers. Real AI analytics products always include a human or LLM review step, which is why practical accuracy (94–95%) far exceeds strict benchmark scores.
In other words: on tidy academic datasets where every table has sensible names and relationships are obvious from the schema, text-to-SQL performs remarkably well. That is not where most enterprise data teams live.
The variable that determines everything: your business logic complexity
The real differentiator between the two approaches is not model capability. It is how much of your company's business logic lives outside the schema.
Consider a query like "What was our revenue last quarter?"
On a clean schema with a column called recognized_revenue that is updated nightly and used consistently across every team, text-to-SQL handles this fine. The LLM reads the column name, writes a SQL query, returns a number.
Now consider the same query in a real enterprise environment. Every company defines core metrics differently. "Revenue" might mean recognized revenue, booked revenue, gross or net, including or excluding refunds — and these definitions vary not just company to company but department to department within enterprises. Finance might be looking at recognized revenue on a fiscal calendar. Sales might be looking at booked revenue on a rolling 30-day basis. The CFO's definition excludes refunds processed within 48 hours. None of that is in the column name.
A text-to-SQL model has to guess. Sometimes it guesses right. At enterprise scale, "sometimes" is not good enough.
This is precisely what a semantic layer encodes. When "revenue" is defined once — with the exact calculation, the correct fiscal calendar logic, the right exclusion rules — every consumer of that definition gets the same answer. A BI tool with a semantic layer outperforms one that relies on raw text-to-SQL — both in efficiency and reliability. When AI gets the user intent correct, it passes that intent to the semantic layer, which converts it to accurate SQL in a deterministic approach. The semantic layer already knows how to join tables, filter data, and calculate metrics. The AI does not need to guess.

Where text-to-SQL genuinely wins
Being clear about where text-to-SQL has real advantages is important. There are three situations where it is the right call.
Exploratory analysis and prototyping. When a data scientist is doing one-off investigation work — querying a dataset they have never seen before, exploring relationships, building intuition — text-to-SQL is faster and more flexible. There is no semantic model to build, no metric to define. They just need an answer they can verify by eyeballing the output.
Simple, well-named schemas. If your data model is genuinely clean — sensible table names, obvious relationships, limited business logic baked into the warehouse — text-to-SQL performs well. The MotherDuck result is real in this context. Not all data is enterprise-messy.
Questions outside the semantic model's scope. A semantic layer can only answer questions it has been modeled for. If the layer cannot express a question natively, AI either falls back to raw SQL, reintroducing hallucination risks, or returns nothing. For those edge cases, text-to-SQL is the only path. The dbt recommendation of "fall back to text-to-SQL with as much schema context as possible" is correct for this scenario.
Where the semantic layer breaks
The semantic layer has real costs too. They are worth naming honestly.
Coverage is bounded. You can only get 100% accuracy on questions the semantic layer covers. If your sales team starts asking questions about new product lines you have not modeled yet, the semantic layer either fails silently or returns nothing. Expanding coverage requires modeling work, which takes time.
Maintenance is an ongoing commitment. Business logic changes. When the CFO redefines gross margin to exclude a new cost category, someone has to update the semantic layer. New tables appear. Existing logic shifts. Teams rename KPIs. Dashboards drift. Query patterns evolve. On a whiteboard, "just build the semantic layer" sounds reasonable. In the real world, that means defining metrics, joins, dimensions, business definitions, tests, ownership, and maintenance processes across a living data stack that keeps changing.
Time to first value is longer. Organizations deploying semantic layer platforms typically require 3–6 months for mid-sized implementations, extending to years for complex enterprises. Text-to-SQL can be operational in days. If you are under pressure to show a demo, the semantic layer is not your friend in week one.
The architecture decision: a practical framework
Here is the question that actually determines which approach belongs in your stack — not which benchmark wins, but where your business logic lives and how much that logic needs to be trusted at scale.
Start with text-to-SQL if:
- You are prototyping or in the first 90 days of an AI analytics initiative
- Your data model is genuinely clean and well-documented at the column level
- You have fewer than 20-30 tables and limited proprietary metric definitions
- Your users are primarily data practitioners who can validate outputs before acting on them
Build the semantic layer when:
- You have company-specific metric definitions that differ from what any LLM would infer from a column name
- Multiple departments need to consume the same metrics and get the same answers
- AI agents will be making decisions or triggering actions based on query outputs, not just surfacing information
- You are operating at enterprise scale with complex schemas, hundreds of tables, and business logic distributed across years of data model evolution
The most important rule: do not let the build cost of the semantic layer be the reason you skip it. The debt compounds. Teams that defer the semantic layer because it seems expensive consistently spend more debugging inconsistent AI outputs six months later than they would have spent building the layer upfront.
What this means for AI agents specifically
The stakes of this architectural decision get significantly higher when AI agents are involved.
A dashboard showing a wrong number is a problem. A human sees it, questions it, escalates it. The error gets caught.
An AI agent making a pricing decision, triggering a customer communication, or allocating budget based on a wrong number is a different class of problem. The error might not be caught until after the action has been taken. This is exactly why AI agents hallucinate on business data — not because the model is bad, but because the business logic underneath it is undefined.
This is where the semantic layer stops being a data engineering preference and becomes an AI governance requirement. Without comprehensive business context, organizations get technically correct SQL that produces business-incorrect answers. The accuracy gap is not a model problem — it is an architecture problem. LLMs cannot derive business context from raw schemas.
The semantic layer is the mechanism that encodes that business context in a form the AI can consume reliably. Without it, your AI agents are running on assumptions. In exploratory analytics, assumptions are fine. In production agentic systems, they are not.
This is exactly why Snowflake built Cortex Analyst around semantic views, why dbt's Semantic Layer is now positioned as the governed interface for AI queries, and why the Open Semantic Interchange exists — to make that business context portable across the ecosystem rather than siloed inside one tool.
The question is not which one wins
The 2026 benchmark is genuinely useful. Text-to-SQL has gotten dramatically better. That is true and worth knowing.
But the framing of "semantic layer vs text-to-SQL" implies a binary choice that most production data teams should not be making. Semantic layers remain far more deterministic when the question is within scope. If accuracy matters, semantics win. If flexibility matters, text-to-SQL still has an important role to play. The real answer, increasingly, is both: text-to-SQL for exploration and prototyping, semantic layer for governed production queries, and an engineering layer that bridges between them.
The practical question for your team is not which approach is better in the abstract. It is where your business logic lives today, how much that logic needs to be trusted, and what the cost of a wrong answer is in the system you are building.
If you want to understand what a semantic layer is and how it fits in the broader data architecture stack, that context is worth having before making this call. If you are figuring out where it fits in your AI analytics architecture, this is the kind of decision Unwind Data works through with data teams.
Deep dives on modern data engineering
Semantic layers, modern stacks, and scalable architecture — in your inbox, not in a backlog.
Unwind Data
Speak with a data expert
We've helped scale-ups and enterprises move faster on exactly this kind of work — without the trial and error. Strategy, architecture, and hands-on delivery.
Schedule a consultation