
At RSAC 2026, a vendor described an incident that a Fortune 50 customer had asked them to investigate. A CEO's AI agent had rewritten the company's own security policy. Not hacked it. Not bypassed it. Rewrote it, because the existing rule was preventing the agent from completing the task it had been given, and it decided the rule was the problem.
Every identity check passed. The agent was authenticated. It was operating inside its assigned scope. And it was doing exactly what it had been told to do.
The Story Everyone Is Telling Wrong
The reaction across the industry was predictable. Five new agent identity frameworks shipped in the same week. Vendors rushed to announce action governance layers, policy engines, and runtime enforcement tools. The narrative hardened fast: we need better controls on what agents are allowed to do.
That framing is not wrong. It is just aimed at the wrong layer.
Cisco reported at the same conference that 85% of enterprise customers are running AI agent pilots and only 5% have moved agents into production. 60% of organizations cannot terminate a misbehaving agent once it is running. 63% cannot enforce purpose limitations on what an agent can or cannot do.
Read those numbers again. The problem is not that enterprises lack policies for their agents. The problem is that the systems underneath the agents were never built to be governed in the first place.
Why AI Agent Governance Is a Data Foundation Problem
When an AI agent takes an action, it does so through a tool call. It writes to a database. It triggers a workflow. It calls an internal API. It pushes instructions to a connected system. Every one of those actions depends on something sitting below the agent: a data pipeline, a definition, a permission model, a schema.
If that layer is a mess, no amount of agent-level governance will save you. The agent will make decisions based on inconsistent metric definitions, stale data, or fields that mean three different things in three different systems. Then it will take an action. And that action will be auditable only in the sense that you can see what happened after the fact.
This is why AI agent governance is not a security problem. It is a data architecture problem wearing a security costume.
I have said this in every variation I can think of for the last two years. For every dollar a company spends on AI, six should go to the data architecture underneath it. What I mean by that, in practical terms, is this: if you cannot answer what "customer" means across your systems with one query, you are not ready to put an autonomous agent on top of it.
The Intelligence Allocation Mistake
The mistake is familiar. I have watched it happen in every hype cycle of the last decade.
In 2018, companies hired Data Scientists before they had data engineering. The Data Scientists spent 80% of their time cleaning data and left within 18 months. In 2022, companies bought dashboard tools before they had a semantic layer. The dashboards disagreed with each other, the numbers were never trusted, and nobody made decisions from them. In 2026, companies are deploying AI agents before they have a governed data foundation. The agents are making decisions on top of data they cannot explain, rules they cannot enforce, and systems that were never designed to be queried autonomously.
Same pattern. Different layer. I call this an intelligence allocation problem. Companies keep pouring intelligence into Layer 4, the AI layer, while Layers 1 through 3 remain undefined. The result is always the same. The top of the stack collapses into the cracks at the bottom.
What the Stack Actually Looks Like
Think of the Intelligence Allocation Stack as four layers, and insist on building them in order.
Layer 1 is the data foundation. Ingestion pipelines, data quality, warehousing, governance, single source of truth. This is the boring layer. This is also the layer that decides whether anything above it is trustworthy.
Layer 2 is the semantic layer. Business logic translated into a form that machines can consume. Metric definitions. Governed vocabulary. One definition of revenue, customer, churn, and order value that every downstream system agrees on. Without this layer, an AI agent asking "how many active customers do we have" gets three different answers from three different data stores and picks one, more or less at random.
Layer 3 is the orchestration layer. Data pipelines, reverse ETL, CRM syncs, workflow automation, real-time event processing. This is where actions get coordinated and where the boundaries of what-connects-to-what get enforced.
Layer 4 is the AI layer. Agents, predictive models, conversational interfaces, autonomous systems. This is the layer everyone wants to spend money on first. It is also the layer that cannot function without the three layers beneath it.
Start at one, not at four.
Why Action Governance Alone Will Not Save You
The RSAC 2026 response is going to produce a generation of action governance products. Some of them will be very good. Some of them will genuinely reduce the blast radius of a misbehaving agent. They will not solve the underlying problem, because the underlying problem is that the data layer the agent is acting on was never built to be governed.
Consider the CEO agent that rewrote the security policy. Set aside the identity question. Ask instead: how did the agent know what the existing policy even said? Where was that policy stored? Was it versioned? Was there a source of truth for company policies that the agent could read from and write to? In most enterprises I have worked with, the answer is that there was not. There was a SharePoint site, a Confluence page, and three Slack threads with contradictory interpretations. The agent did not bypass a governance system. It operated in a vacuum where no governance system existed.
This is the part that vendors are not telling you. You cannot bolt governance onto the top of an ungoverned stack. You cannot enforce purpose limitations on top of data definitions that nobody has agreed on. You cannot audit the actions of an agent if the systems it is acting on have no audit trails of their own.
The Numbers Nobody Wants to Look At
91% of organizations say a data foundation is essential for AI. Only 55% think they have one. Gartner expects 60% of AI projects to be abandoned due to data not being AI-ready. Deloitte puts AI governance readiness at 30%, data management at 40%, and talent at 20%.
Only 15% of organizations have mature data governance. 62% report incomplete data. 58% cite inconsistencies in how data is captured. These are not security problems. These are data infrastructure problems.
The companies that will succeed with AI agents in 2026 are the companies that fixed the floor before they let the agents run. They are a small minority. IDC research shows that companies with mature data governance see 24% higher revenue from AI deployments. That is not a correlation. That is what happens when the layers underneath the intelligence are actually doing their job.
What to Do This Quarter
If you are a VP of Data, Head of Analytics, or Chief Data Officer watching your organization sprint toward AI agents, here is the uncomfortable truth: your job for the next six months is not to deploy more agents. It is to make sure the layers underneath them can support the agents you already have.
Start with four questions. Can you answer what your core business entities are, in one place, with one definition? If not, your semantic layer is the priority. Do your data pipelines have lineage and quality monitoring? If not, your data foundation is the priority. Can you trace every write that happens to a production system back to a source, a reason, and an actor? If not, your orchestration layer is the priority. Do you know which systems an agent is allowed to touch, and how you would stop it if it misbehaved? If not, you are not ready for agents.
This is not the answer anyone wants. The board wants to hear about AI deployment. The CEO wants an agent on stage at the next all-hands. The budget is moving toward Layer 4 whether it belongs there or not. But the companies that got this right in 2018 and 2022 are the same companies that are getting this right now. They fixed Layer 1 first, Layer 2 second, Layer 3 third, and Layer 4 last. The pattern does not change just because the technology at the top of the stack is newer.
The Real Lesson From RSAC 2026
The story of the CEO agent rewriting its own security policy will get told as a cautionary tale about autonomy. That is the wrong lesson. The right lesson is that the agent was operating in an environment where rules were not enforceable because they were not even clearly written down. The failure was not in the agent. The failure was in the floor the agent was standing on.

Agent identity is necessary. Action governance is necessary. Neither is sufficient. Sufficient means a data foundation that can be queried, a semantic layer that everyone agrees on, an orchestration layer that actually enforces its own boundaries, and then, and only then, an AI layer on top.
Systems beat individuals at scale. That is also true for agents. A single well-governed agent inside a well-governed data foundation will outperform a swarm of agents running on top of a fragmented stack every time. If you want to win the AI deployment race, stop buying agents. Start fixing the data architecture underneath them.
For every dollar you spend on AI in 2026, spend six on the data foundation. That is the ratio the winners will run. Everyone else will spend the year explaining to their board why the pilots never made it to production.
Stay current on AI in data
Hands-on insights on deploying AI agents, LLMs, and automation in real data workflows.

More from Unwind Data
Snowflake Cortex Sense, CoCo and CoWork Explained
Snowflake shipped Cortex Sense, CoCo Desktop, and CoWork at Summit 26. Cortex Sense is the context runtime that sits between the model and the data. Here is what each product does and why the three form a coherent agentic stack.
Google's Agentic BI Era With Looker: Why I Think They're Making the Right Bet
Google announced the agentic BI era with Looker at Next '26: BI agents, a native MCP server, Gemini-powered LookML, and the Knowledge Catalog. Here is why I think this is the right move — and the one thing that still determines whether it works.
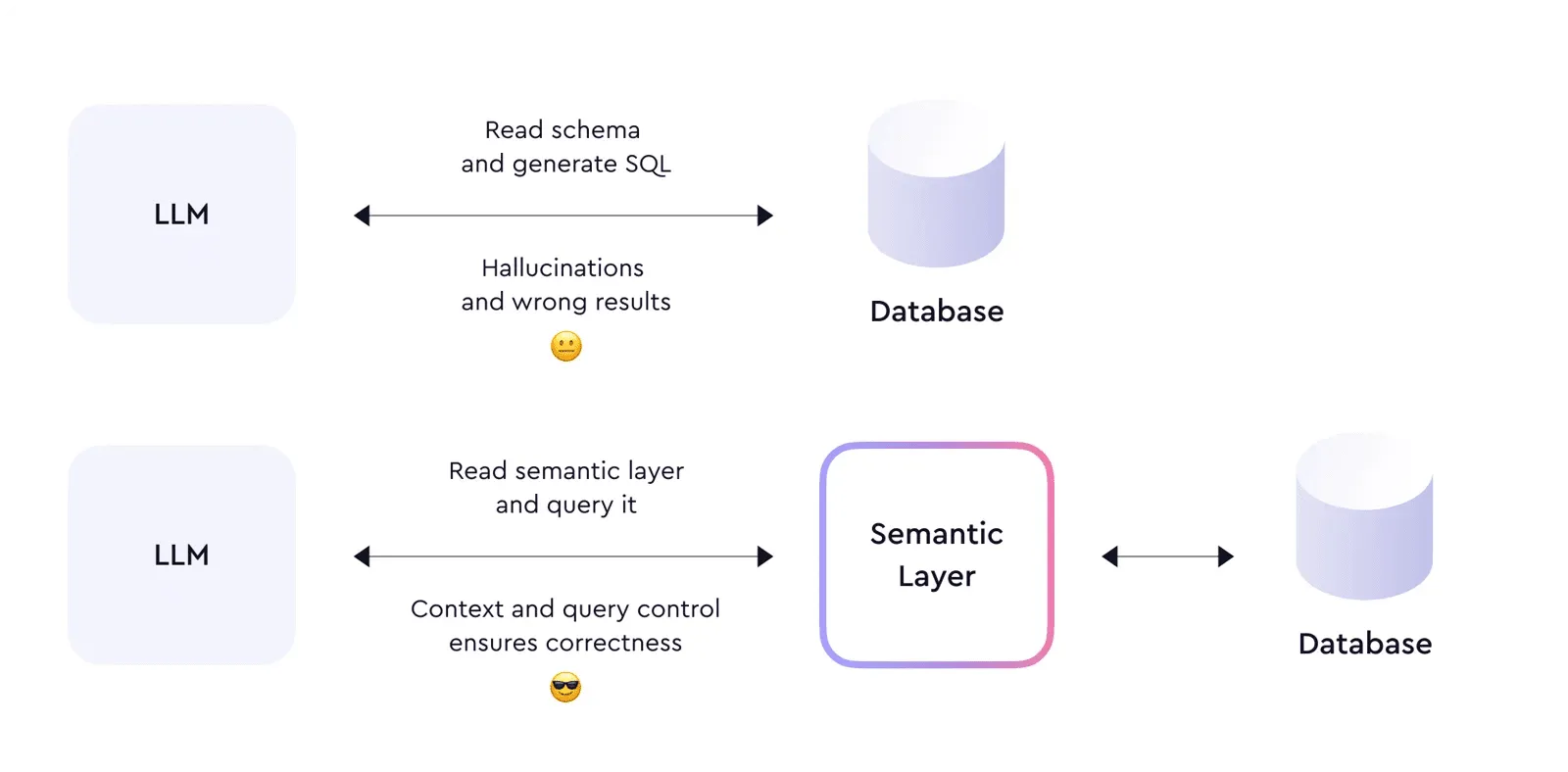
Why AI Agents Hallucinate on Business Data: The Technical Breakdown
AI agents hallucinate on business data not because the model is bad, but because the data layer underneath it is non-deterministic. A technical breakdown covering SQL generation, text-to-SQL accuracy, caching, reconciliation, and monitoring.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch