Why AI Agents Keep Failing and the Fix Is Not a Better Model
AI agent adoption surged 327% in four months. Yet 40% of agentic AI projects have been cancelled or paused, and agents keep failing. The bottleneck is not the model. It is the data infrastructure underneath it.

327%. That is how much enterprise AI agent adoption grew in just four months, according to the Databricks 2026 State of AI Agents report. In the same period, 40% of agentic AI projects were cancelled or paused, and agents keep failing. Those two numbers tell you everything you need to know about where enterprise AI strategy stands right now.
Companies are not short on ambition. They are short on data infrastructure. And until that changes, the smartest AI agents in the world will keep hallucinating, compounding errors, and burning through budgets without delivering measurable results.
The Compounding Error Problem Nobody Talks About
Here is a number that should scare every VP of Data reading this. If your AI agent achieves 85% accuracy on each individual step in a workflow, a 10-step process succeeds roughly 20% of the time. That is not a hypothetical. That is how probability works when errors compound across sequential tasks.
To get a 10-step agentic workflow above 80% success, you need per-step accuracy above 98%. And 98% accuracy requires something most enterprises do not have: clean, well-structured, current data at every single input point.
This is the math that makes AI agents data quality dependent in a way that chatbots and dashboards never were. A chatbot can give a vaguely wrong answer and nobody dies. An autonomous agent that books the wrong vendor, misclassifies a compliance flag, or sends the wrong customer data to the wrong system creates cascading failures that are expensive and sometimes irreversible.
75% of Companies Plan to Deploy Agents. 28% Have Zero Confidence in Their Data.
Close to 75% of businesses plan to deploy AI agents by the end of 2026. At the same time, 28% of US firms report zero confidence in the data quality feeding their agents. More than half of all agents currently deployed run without any security oversight or logging.
Let that sink in. We are deploying autonomous systems on top of data foundations we do not trust, with no audit trail for what those systems are doing.
This is not an AI problem. This is a data governance problem that existed long before anyone said the word "agentic." The difference is that bad data governance used to mean a wrong number on a dashboard. Now it means an AI agent making real decisions with real consequences, operating on incomplete or inconsistent information.
The Intelligence Allocation Mistake
I have been building data infrastructure for companies since 2018, when I co-founded a data consultancy that we grew and eventually sold. Across fintech, e-commerce, SaaS, and sustainability, the pattern is always the same. Companies allocate their intelligence to the wrong layer.
Think of your technology stack as four layers. Layer 1 is your data foundation: data governance, data quality, ingestion pipelines, warehousing, your single source of truth. Layer 2 is the semantic layer, where business logic gets translated into a vocabulary that machines can understand. Layer 3 is orchestration: data pipelines, CRM syncs, reverse ETL, workflow automation. Layer 4 is where AI lives: agents, conversational AI, autonomous systems, predictive models.
For every dollar companies spend on AI at Layer 4, they should be spending six on the data architecture underneath it. Instead, most companies are doing the opposite. They start at Layer 4 and work backwards, which is like installing a penthouse suite on a building with no foundation.
The Databricks report confirms this pattern at scale. While AI agent deployments surged 327%, only 19% of enterprises have successfully deployed agents at production scale. The other 81% are stuck in pilot purgatory, and 42% of organizations identify data access and data quality as the primary barrier to getting out.
What the Companies Getting It Right Actually Do
The 19% of companies successfully running AI agents at scale share a common pattern. They invested in their data foundation before they invested in AI. According to the same Databricks report, companies that implemented AI governance pushed 12 times more projects into production. Organizations using evaluation tools moved nearly 6 times more AI systems from pilot to production.
This is not a coincidence. It is the direct result of having a data strategy that prioritizes infrastructure over experimentation.
Here is what that looks like in practice. These companies built governed data pipelines before they built agents. They defined their semantic layer, so every department works from the same metric definitions. They implemented data quality checks at ingestion, not as an afterthought. And they created audit trails for every piece of data an agent touches.
The result? A 60 to 80% reduction in processing time for routine transactions and a 40% boost in overall data team productivity. Not because they had better models. Because they had better data engineering.
The 2018 Pattern Is Repeating
In 2019, I wrote that every company was about to hire a wave of Data Engineers to clean up the mess that years of unstructured data had created. That prediction came true. The modern data stack movement, tools like dbt, Snowflake, Fivetran, and Looker, emerged specifically to solve the data foundation problem.
Now, in 2026, I could rewrite that article word for word. The mess is the same. The stakes are higher. In 2019, bad data architecture meant your dashboards were unreliable. In 2026, bad data architecture means your AI agents are unreliable. And unreliable autonomous systems are not just annoying. They are a business risk.
The Gartner prediction that 60% of AI projects will be abandoned due to data not being AI-ready is not a future scenario. It is happening now. Only 15% of organizations have mature data governance. 62% report incomplete data. 58% cite capture inconsistencies. These numbers have barely moved in three years, even as AI spending has exploded.
What Poor Data Quality Actually Costs
Recent 2026 benchmarks from Gartner and IBM put the number at $12.9 million to $15 million annually per organization. That is the cost of poor data quality and siloed data architecture before you factor in failed AI projects.
Now add the AI waste. Companies are spending millions on model development, compute, and agent frameworks that will never reach production because the data underneath is not ready. IDC found that companies with mature data governance see 24% higher revenue from AI. Which means the companies without it are leaving a quarter of their potential AI returns on the table.
The EU AI Act enforcement cycle that began in 2026 adds another dimension. High-risk AI systems are now subject to stringent transparency, documentation, and oversight requirements. If your data governance is not mature enough to support AI agents, it is definitely not mature enough to demonstrate compliance with regulatory frameworks that require full traceability of how AI systems make decisions.
Fix the Floor Before You Let the Agents Run
If you are reading this and your organization is planning to deploy AI agents, or has already started and hit a wall, here is the uncomfortable truth. The fix is not a better model. OpenAI, Anthropic, Google, and the rest are shipping improvements every month. Model capability is not the bottleneck.
The bottleneck is your data infrastructure. Specifically:
Your data quality. Can every system that feeds an agent guarantee 98%+ accuracy? If not, your multi-step workflows will fail more often than they succeed.
Your semantic layer. Do your AI agents and your human teams operate from the same metric definitions and business logic? If your agents are working from a different version of reality than your analysts, you have a consistency problem that no model can solve.
Your data governance. Do you know where your data comes from, who changed it, and whether an agent is allowed to act on it? Without lineage, access controls, and audit trails, you are flying blind with autonomous systems at the controls.
Your data pipelines. Is your data fresh enough for real-time agent decisions? Batch processing that was fine for weekly dashboards is not fine for agents making customer-facing decisions every second.
Start at One, Not at Four
The companies that will win the AI agent race are not the ones with the biggest model budgets. They are the ones that built their data foundation first. Systems beat individuals at scale. And right now, the system that matters most is not the AI layer. It is everything underneath it.
88% of companies use AI. Only 39% see measurable impact. The gap between those two numbers is not a technology problem. It is a data architecture problem. And the only way to close it is to start at Layer 1.
Stop allocating all your intelligence to the top of the stack. Fix the foundation. Then let the agents run.
Stay current on AI in data
Hands-on insights on deploying AI agents, LLMs, and automation in real data workflows.

More from Unwind Data
Snowflake Cortex Sense, CoCo and CoWork Explained
Snowflake shipped Cortex Sense, CoCo Desktop, and CoWork at Summit 26. Cortex Sense is the context runtime that sits between the model and the data. Here is what each product does and why the three form a coherent agentic stack.
Google's Agentic BI Era With Looker: Why I Think They're Making the Right Bet
Google announced the agentic BI era with Looker at Next '26: BI agents, a native MCP server, Gemini-powered LookML, and the Knowledge Catalog. Here is why I think this is the right move — and the one thing that still determines whether it works.
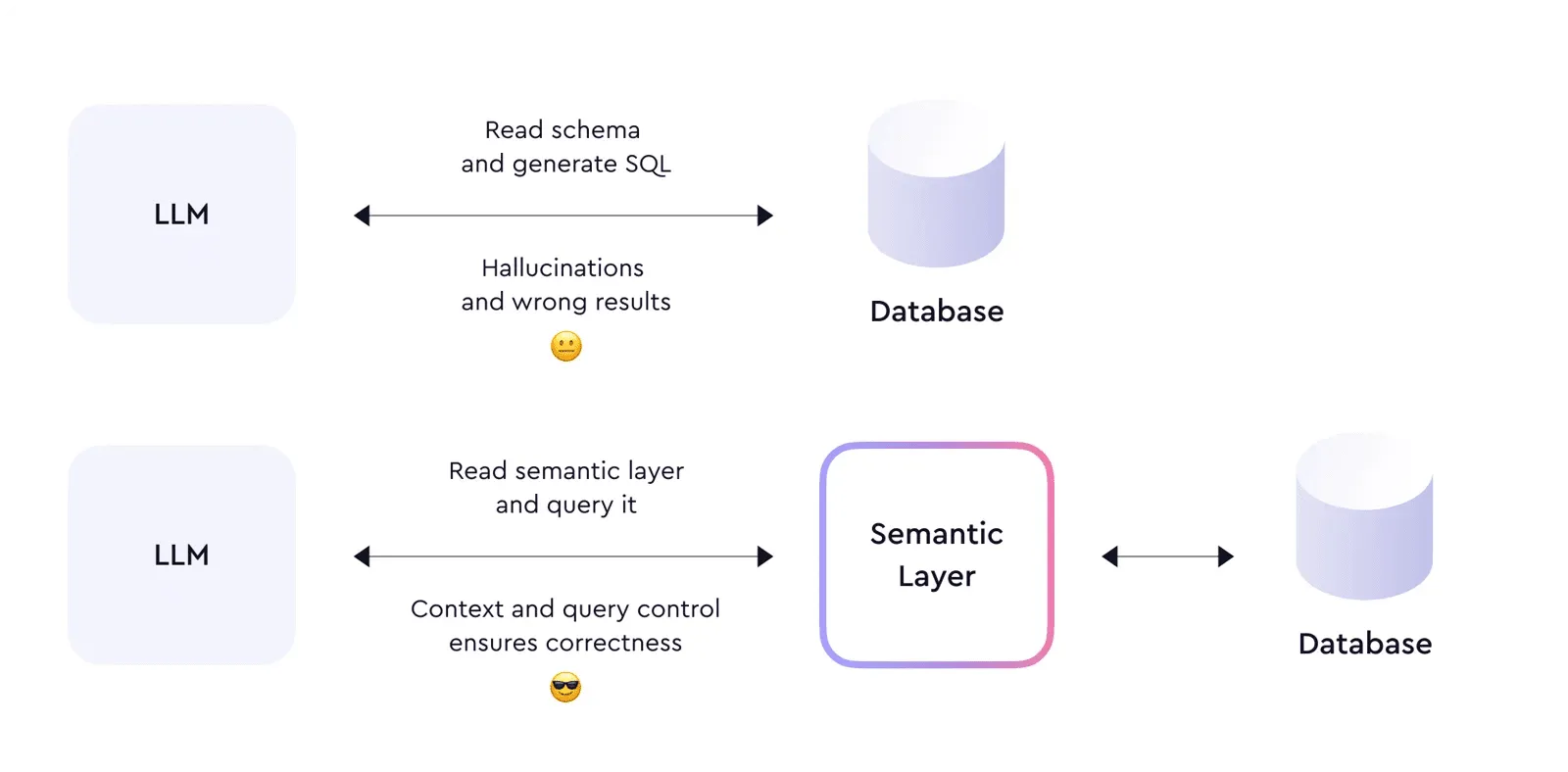
Why AI Agents Hallucinate on Business Data: The Technical Breakdown
AI agents hallucinate on business data not because the model is bad, but because the data layer underneath it is non-deterministic. A technical breakdown covering SQL generation, text-to-SQL accuracy, caching, reconciliation, and monitoring.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch