Gartner Semantic Layer Warning: AI Agents Will Fail Without Context
Gartner formally warned that skipping semantic foundations will cause AI agents to hallucinate, waste budget, and create governance risk. Practitioners already knew this. Here's what the context layer is and what building it actually requires.

Gartner Predicted This. Practitioners Built It Years Ago.
On May 11, 2026, Gartner issued a formal warning at their Data and Analytics Summit in London: organizations that skip semantic foundations in their agentic AI stack will face inaccurate agents, wasted budget, and mounting governance risk. The Gartner semantic layer prediction from Rita Sallam, Distinguished VP Analyst: companies that prioritize semantics in AI-ready data infrastructure will increase agentic AI accuracy by up to 80% and reduce costs by up to 60% by 2027.
Those are not incremental numbers. That is the difference between an AI investment that compounds and one that corrodes.
If you have been building a semantic layer as part of your data architecture, this is validation. If you haven't, it is a deadline.
What Gartner Actually Said
Sallam's exact words at the summit: "Agentic AI outcomes depend on context including semantic representations of data. Without context, a clear understanding of the specific relationships and rules within an organization's data, AI agents cannot operate accurately and are far more likely to hallucinate, introduce bias and produce unreliable results."
This is not a new finding for practitioners who have built these systems. It is, however, a significant shift in how the world's most influential technology analyst firm is framing the agentic AI failure problem. When Gartner puts this in formal guidance, it changes how organizations budget and prioritize. It changes what a CFO asks in the next board meeting.
Gartner's formal guidance now tells data and analytics leaders to establish a context layer as a core component of their data infrastructure. The precise language is worth quoting: "Traditional schema-based data models alone no longer suffice for agentic AI because they lack business context and data meaning."
What Gartner calls a context layer has another name that data teams have been building with for years.
The Context Layer Already Has a Name
The semantic layer is the context layer Gartner is describing.
A semantic layer sits between your data warehouse and everything that consumes data: BI tools, AI agents, data APIs, downstream pipelines. Its job is to translate raw data into the concepts your business actually uses. Revenue is not a column in a database. It is the specific calculation your finance team agreed on in Q3 of last year, net of refunds, excluding intercompany transfers, segmented by region. The semantic layer holds that definition. Without it, every downstream system either recomputes it differently or gets it wrong.
For BI tools, an inconsistent semantic foundation produces metric drift: two dashboards showing different revenue figures for the same period. The problem is visible, but the consequences are manageable. Someone catches it in a meeting and flags it for the data team.
For AI agents, the same inconsistency produces hallucinated answers at scale, biased automated decisions, and governance failures that are often invisible until they surface in a compliance audit or a customer complaint. The consequences are not manageable by a data team on a Tuesday morning.
This is exactly why Gartner framed the context layer as a cost-control and trust strategy rather than a technical optional. Their quote: "By reducing errors and increasing trust, semantics will push organizations to budget for semantic capabilities as a non-negotiable foundation."
Why AI Agents Fail Without Semantic Foundations
Most organizations currently deploying agentic AI are connecting agents directly to raw data tables or lightly structured schemas. The agent is smart. The data it queries is not.
When an AI agent hits a raw table, it has to infer what each column means from the column name and whatever sparse metadata exists. In practice, that means the agent is making educated guesses about business logic that took your team years to align on. Revenue calculation. Customer segmentation rules. How you define an active user. What counts as a conversion in your funnel. Whether a cancelled order still counts toward a salesperson's quota.
Those guesses are almost always wrong in the specific, high-stakes edge cases that matter most. And they are wrong differently every time the agent runs the same question with slightly different phrasing, or when the underlying table structure changes in a deployment no one told the AI team about.
In almost every engagement where I have been brought in to diagnose why an AI agent implementation is underperforming, the root cause is the same: the agent is running on raw or minimally structured data with no semantic layer underneath it. The team spent the budget on the model, the infrastructure, and the interface. They skipped Layer 2.
The result is exactly what Gartner is warning about: hallucination, bias, and unreliable outputs. Not because the model is bad. Because the data layer underneath it has no business context baked in. We covered the technical mechanics of this in detail in Why AI Agents Hallucinate on Business Data. Gartner's formal guidance is now confirming what that analysis showed: the hallucination problem is a data problem, not a model problem.
The Intelligence Allocation Stack and Where Gartner's Context Layer Lives
At Unwind Data, we use a framework called the Intelligence Allocation Stack to explain where organizations go wrong when building AI systems. The stack has four layers:
- Layer 1: Data Foundation — Data governance, data quality, ingestion pipelines, a single source of truth
- Layer 2: Semantic Layer — Business logic translated for machines, governed metric definitions, a shared and consistent vocabulary for every data consumer
- Layer 3: Orchestration — Pipelines, APIs, workflow automation, real-time event processing
- Layer 4: AI Agents — The intelligence layer that interacts with users and executes tasks
The core problem we see with enterprise AI projects is that organizations start at Layer 4. They build the AI agent before they have built the foundation underneath it. They allocate intelligence to the top of the stack before the bottom is stable. It is the equivalent of running a precision instrument on uncalibrated inputs and expecting precise outputs.
Gartner's "context layer" is Layer 2. Their warning that organizations failing to adopt comprehensive context structures will "perpetuate data inefficiencies and face heightened financial costs, as well as legal and reputational damage" is a formal description of what happens when you run Layer 4 without Layer 2 beneath it.
For every dollar companies spend on AI, they should be spending six on the data architecture underneath it. That ratio is not marketing language. It is what the failure patterns actually cost when you build in the wrong sequence.
The Governance Dimension That Will Not Wait
The cost and accuracy arguments for semantic foundations are well understood by data teams, even when they are not always acted on. The governance argument is newer and arriving faster than most organizations have planned for.
Gartner expects regulators to demand greater semantic transparency. Boards will treat semantic governance as both a strategic risk and a competitive opportunity. That is not a 2028 forecast. The EU AI Act enforcement begins in August 2026, three months from now. Organizations deploying AI systems in regulated contexts are already in scope for requirements that trace directly back to data quality, data provenance, and the consistency of how business logic is applied across automated systems.
If your AI agent calculates customer risk differently depending on which data path it took to reach the answer, you have a governance problem. If you cannot explain to a regulator why your AI agent reached a specific decision and trace that reasoning back to the governed metric definitions in your semantic layer, you have a compliance problem that a better model cannot fix.
The semantic layer is not just the accuracy solution. It is the audit trail. It is what makes an AI system explainable, and increasingly what regulators will require before that system can operate in a regulated context. We covered the structural relationship between AI agent governance and data foundations in AI Agent Governance Is a Data Foundation Problem. The Gartner announcement adds institutional weight to that argument: semantic governance is now formally on the board risk register.
What the 80% Accuracy Improvement Actually Requires
Gartner's prediction is striking, but it comes with a specific condition: organizations that prioritize semantics in AI-ready data. What does "prioritizing semantics" actually require in practice? Three things that are deceptively simple to describe and genuinely difficult to execute.
Governed metric definitions. Every business metric that an AI agent might query needs a single, agreed-upon definition stored in the semantic layer. Revenue, churn, conversion rate, active users, customer lifetime value. These cannot live in five different BI reports running five different formulas. They need one canonical definition, version-controlled and owned, that every downstream system reads from.
Business context attached to data. Column names like txn_amt or usr_flg_1 are meaningless to an AI agent without a semantic layer that translates them into business concepts. The semantic layer holds the vocabulary: this column is "transaction amount in EUR, net of VAT, as reported at time of booking." That context is what separates a query returning a correct answer from one that confidently returns a wrong one.
A shared semantic vocabulary across all systems. If your AI agents, your BI tools, and your data pipelines all compute the same concept through different logic, you do not have a semantic layer. You have fragmentation with a better name. The semantic layer has to be the single layer that all data consumers query from. Not one of several options. The canonical one.
Building this is not primarily a technical project. It is an organizational alignment project that happens to be implemented technically. The companies that get to 80% accuracy improvement are the ones that invest in the alignment work before they deploy the agents, not the ones that add a semantic layer on top of an already-running agentic workflow and hope the accuracy catches up.
The Tooling Market Gartner Will Now Accelerate
Gartner's formal semantic layer guidance will accelerate a market that was already moving. Tools like the dbt Semantic Layer, Cube, Omni, and Snowflake's native Semantic Views are all competing to serve as the semantic layer in the modern data stack. The Open Semantic Interchange standard, which launched this year to enable portability between these tools, is gaining adoption as organizations try to build semantic coherence without locking into a single vendor's implementation.
The tool choice matters less than the architectural decision: where does business logic live in your stack, and who owns it? Those two questions are organizational before they are technical. And the organizations that answer them clearly before deploying agentic AI are the ones Gartner is predicting will see 80% accuracy improvements and 60% cost reductions.
Our architecture guide for connecting your semantic layer to AI agents covers the technical decisions in detail. The Gartner announcement does not change which tool to pick. It changes how urgently you need to make the decision.
What to Do Before Your Next AI Agent Deployment
If you are running AI agents in production today without a semantic layer underneath them, you are already experiencing the accuracy and cost problems Gartner is describing. They may not carry that label. They look like "the AI gives inconsistent answers depending on how you phrase the question" or "we have to manually verify the outputs before acting on them" or "the agent worked in the demo but not in production." Those are semantic foundation problems.
The path forward is not to rebuild everything before deploying anything. It is to identify the highest-stakes metrics and business concepts that your AI agents query and move those definitions into a governed semantic layer first. One domain. One team. One source of truth. Then expand.
Gartner has now made the formal case for what practitioners have been building toward for years. Layer 2 is not a nice-to-have infrastructure investment. According to Gartner's 2027 prediction, it is the difference between an agentic AI program that delivers and one that wastes budget while creating compounding governance risk.
According to every engagement where I have had to explain why the AI is hallucinating, it always was.
If you want to understand where your data architecture stands before your next agentic AI deployment, the architecture assessment starts here.
Deep dives on modern data engineering
Semantic layers, modern stacks, and scalable architecture — in your inbox, not in a backlog.

More from Unwind Data
AtScale vs dbt Semantic Layer: Enterprise vs Engineering-First
AtScale and dbt Semantic Layer both promise a single source of truth for metrics. But they represent two completely different architectural philosophies and serve two different organizational realities. Here is the head-to-head comparison that vendor demos will not give you.
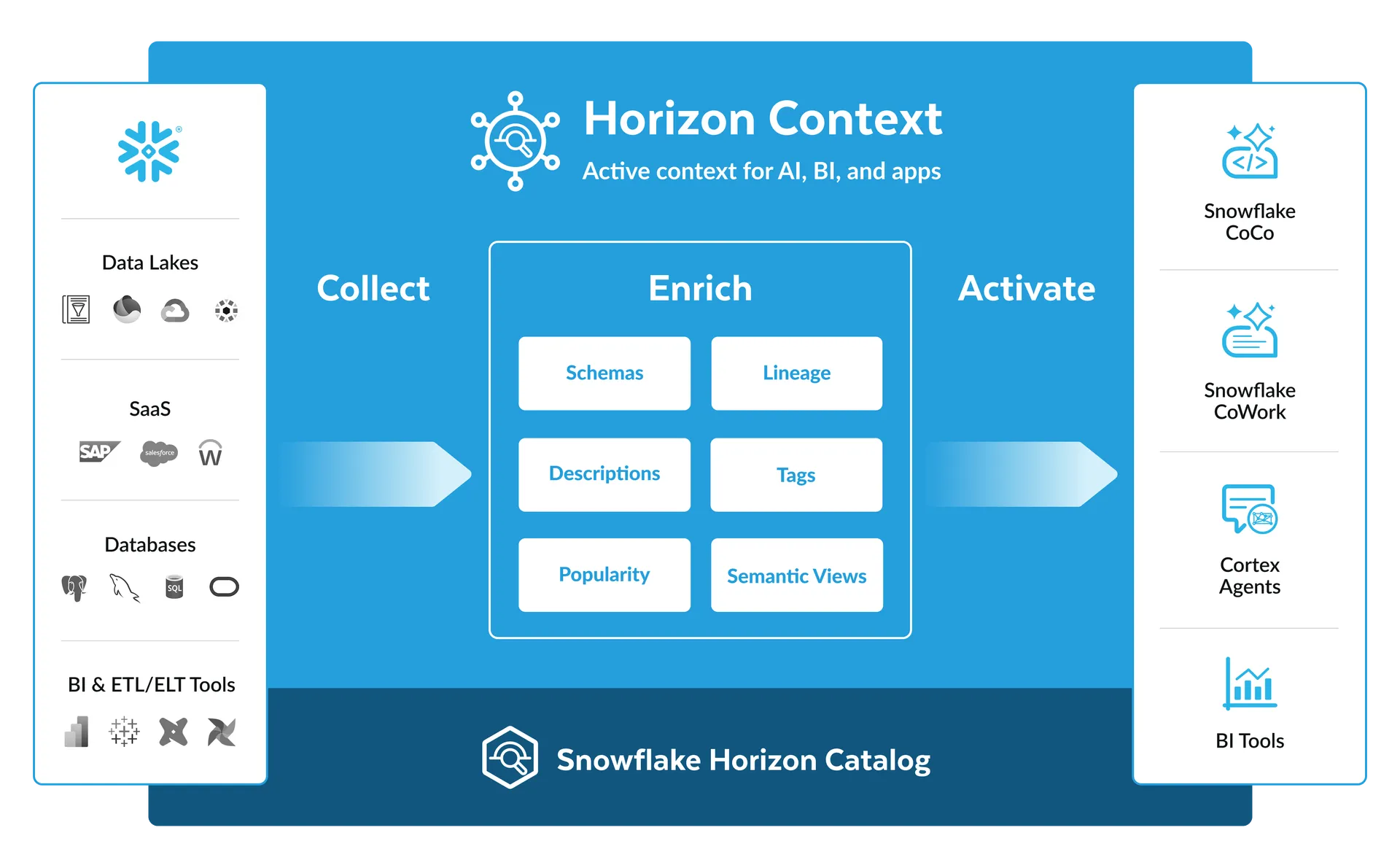
Snowflake Horizon Context: What It Does to the OSI
Snowflake announced Horizon Context at Summit 26: a unified active context layer sitting on Horizon Catalog, serving AI agents, BI tools, and the Cortex stack from one place. Here is what it actually is, and what it does to the OSI question.

How to Connect Your Semantic Layer to AI Agents: Architecture Guide
AI agents connected directly to the warehouse break in production. Here is the vendor-neutral architecture guide for connecting your semantic layer to AI agents using MCP, OSI, and A2A.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch