Snowflake Cortex Sense, CoCo and CoWork Explained
Snowflake shipped Cortex Sense, CoCo Desktop, and CoWork at Summit 26. Cortex Sense is the context runtime that sits between the model and the data. Here is what each product does and why the three form a coherent agentic stack.
Snowflake shipped two agent surfaces at Summit 26. One for builders. One for knowledge workers. The press coverage has been largely focused on the rebrand: Cortex Code is now CoCo, Snowflake Intelligence is now CoWork. The names are easier to say, and yes, that matters.
But the rebrand is not the story. The story is what sits between those two surfaces and the data underneath them. Snowflake called it Snowflake Cortex Sense. It is in private preview, it got a fraction of the stage time that CoWork and CoCo received, and it is the most consequential thing Snowflake announced at Summit 26.
Snowflake Cortex Sense: the context runtime agents have been missing
Every enterprise AI pilot eventually hits the same wall. The demo worked because the agent ran on curated, well-described data in a controlled environment. Production is different. Production data has ambiguous column names, undocumented business rules, metric definitions that exist only in the head of the analyst who built the original dashboard in 2019.
Baris Gultekin, Snowflake's VP of Product and AI, used a concrete example during Summit analyst sessions that cuts to the core of the problem. Someone asks an AI agent whether Q3 ACV was up. A generic agent will answer correctly in the general sense. But the business definition requires excluding free-tier activity from ACV. Without that rule encoded somewhere the agent can access at runtime, the answer is confidently wrong. Not wrong in a way that looks wrong. Wrong in a way that gets presented in the board deck.
This is the kind of failure that kills enterprise AI trust. Not dramatic model hallucinations. Subtle definition errors that compound into bad decisions made confidently.
Snowflake Cortex Sense is designed to solve this at the infrastructure level. It is not a prompt engineering fix. It is not a per-agent configuration step. It is a managed runtime that automatically brings together the data, business definitions, and operational knowledge an agent needs before it answers a single question.
The accuracy impact is reported at nearly double compared to agents operating without it, reaching 83% on enterprise benchmark tasks. That delta is the difference between a demonstration and a deployment.
What Cortex Sense actually pulls from
Cortex Sense builds its context runtime from multiple layers simultaneously. This is what separates it from a semantic layer lookup or a catalog search. It draws from:
Semantic views. The governed business definitions built into Snowflake Horizon Catalog. Metric definitions, dimension relationships, governed vocabularies. The "what does this term mean" layer encoded by your data team.
Structured and unstructured data. Not just the warehouse tables, but the broader data estate: documents, wikis, runbooks, product specs, anything that holds institutional knowledge about how the business works.
Business glossary and metadata. Ownership metadata, data lineage, quality signals, descriptions. The operational context around data, not just the data itself.
Agent skills and past interactions. Cortex Sense learns from what agents have done before. If an agent has answered similar questions in the past, those patterns inform how context is assembled for new queries.
Prebuilt plugins for business roles. Cortex Sense ships with role-specific plugins for finance and sales teams. Each plugin packages the skills, business rules, and MCP connectors relevant to that function into a ready-to-deploy context bundle. A sales agent built on Cortex Sense inherits CRM definitions, pipeline stage meanings, and revenue attribution rules out of the box, without a data engineer manually configuring them per agent.
The architecture matters here. Cortex Sense is not a one-time enrichment. It is a runtime. Every time an agent executes a task, Cortex Sense assembles the relevant context dynamically, from the current state of the data estate. Business definitions change. Metric thresholds change. Cortex Sense reflects those changes automatically. The agents stay current without manual updates.
This is the piece that makes the Intelligence Allocation Stack concrete in practice. You build Layer 1 (governed data), Layer 2 (semantic definitions), and Layer 3 (reliable pipelines). Cortex Sense is what connects Layer 2 to Layer 4 at runtime, not just at design time. Without this connection, even a well-built semantic layer stays static while agents guess at business context from raw schema.
For a deeper look at why agents hallucinate on business data without this kind of context, see our breakdown of why AI agents hallucinate on business data. Cortex Sense is Snowflake's infrastructure answer to exactly that problem.
The relationship between Cortex Sense and Horizon Context
These two announcements are related but distinct, and the distinction matters for how you design your data architecture around them.
Horizon Context is the static layer. It is where business definitions live: semantic views, metadata connectors, the governed vocabulary your data team maintains. It is the catalog that says what your data means.
Cortex Sense is the dynamic layer. It is the runtime that assembles the relevant context at query time, drawing from Horizon Context among other sources, and surfaces it to the agent in a form it can use immediately. Horizon Context defines the context. Cortex Sense activates it.
Snowflake is making a coherent infrastructure argument: governed semantics need to be both persistent (Horizon Context) and dynamic (Cortex Sense) to be genuinely useful for agentic AI. A static semantic layer that agents have to look up manually is insufficient. A runtime that assembles context automatically from governed definitions is the production architecture.
For the full analysis of Horizon Context and what it means for the OSI standard, see our post on Snowflake Horizon Context and the OSI question.
Snowflake CoCo Desktop: the coding agent goes native
CoCo, formerly Cortex Code, launched in February 2026 and reached 7,100 customer accounts by Summit. That is the fastest product adoption in Snowflake's history. The informal name came first: data engineers started calling it CoCo internally before the rebrand was official. Snowflake made it official at Summit.
The Summit announcement expanded CoCo across every surface where builders actually work. CoCo Desktop is now generally available: a standalone native application that runs outside the Snowflake web interface. The practical implication is that builders no longer need a browser tab open to work with CoCo. It runs as an application alongside the IDEs, terminals, and notebooks that data engineers live in.
The surface expansion announced at Summit:
CoCo Desktop (GA). Native application, available now. Works with VS Code extension. Includes a shielded local sandbox to protect sensitive files and system resources during local execution.
Cloud Agents. Start a task in Snowsight, then let it run in the background. The laptop does not need to stay open. Long-running pipeline tasks, model evaluation jobs, data quality assessments: all executable as background cloud tasks that report back when complete.
Agent SDK. Integrate CoCo capabilities directly into existing workflows. Teams that have built internal tooling around their data pipelines can embed CoCo as a programmable component rather than requiring engineers to switch to a separate surface.
Excel plugin and Slack integration (coming soon). Extensions that bring CoCo into the tools that still dominate enterprise workflows, regardless of what the modern data stack looks like underneath them.
Automations. Recurring and event-driven workflows for monitoring, validation, and operational processes. Covered by role-based access control and audit trails. The shift from "CoCo answers my question" to "CoCo runs my operational processes."
The most technically significant addition to CoCo is what Snowflake describes as a native tools approach. Rather than falling back on bash-based workflows, CoCo uses native tooling for Snowflake, dbt, and Airflow. This keeps the agent's work close to the data systems it is operating on, maintaining the governance and lineage context that bash-style execution would bypass.
For data teams evaluating whether CoCo is worth adopting over existing coding agents, the differentiator is this governance-native orientation. A general-purpose coding agent can write Snowflake SQL. CoCo does it with awareness of your schemas, lineage, access controls, and semantic definitions built in. The output is not just working code. It is code that respects the data architecture you have already built.
Fanatics, one of CoCo's production customers, described the impact directly: "Engineers who used to spend days untangling pipeline issues and modeling data can now resolve those problems in hours, freeing them to build and ship new capabilities exponentially faster."
Snowflake CoWork: the knowledge worker agent
CoWork, the rebrand of Snowflake Intelligence, is the other side of Snowflake's two-surface strategy. Where CoCo serves builders, CoWork serves knowledge workers: finance analysts, sales teams, product managers, executives who need answers from data but will not write SQL to get them.
Christian Kleinerman described CoWork as Snowflake's answer to a persistent structural problem: enterprise data is not reaching the people who need it. Most employees do not write SQL. CoWork eliminates that mediation for the knowledge worker. CoWork accounts have more than doubled quarter over quarter. The signal is that this is not a feature power users are exploring. Business teams are adopting it as a workflow change.
The new CoWork capabilities at Summit 26:
Artifacts. Analysts build and publish fully interactive dashboards that colleagues can explore through natural conversation, grounded in live Snowflake data rather than static PDF exports. The Artifacts feature collapses the gap between "I built this analysis" and "the rest of the team can work with this analysis." Interactive, conversational, and live.
Deep Research. Multi-step reasoning over structured and unstructured enterprise data. CoWork searches across the full data estate, combining SQL-queryable tables with unstructured documents, to answer complex questions that previously required an analyst to manually assemble multiple sources. Not a chatbot lookup. Agent-orchestrated research that synthesizes answers from wherever the relevant information lives.
User Memory. CoWork learns how individual users work. Preferences, common questions, specific definitions they use. A CFO who consistently wants revenue reported excluding specific line items gets that behavior by default, not by re-prompting every session.
Cortex Sense integration. CoWork natively consumes Cortex Sense context. The knowledge worker who asks about Q3 ACV gets the answer grounded in the business definition, not the raw column, because Cortex Sense is assembling the relevant context at runtime before the answer is generated.
iOS app (GA soon) and prebuilt plugins for finance and sales. CoWork extends to mobile, and the role-specific plugins mean a sales leader gets a production-ready agent for their function, not a blank canvas they have to configure from scratch.
Baris Gultekin described CoWork as "your personal work agent. That means a lot of connectors to work context, email, calendar, Slack and other connectors." The framing is deliberate. This is not a BI tool replacement. It is a work agent grounded in your Snowflake data, with connectors to the operational tools where work actually happens.
The three pieces as a coherent stack
The three announcements form a coherent architecture when you see them together rather than individually.
Cortex Sense is the shared context layer. It lives in the middle of the stack and serves both surfaces. It draws from Horizon Context for semantic definitions, from the broader data estate for unstructured context, and from agent history for learned patterns. It is the layer that turns a capable model into an agent that understands your specific business.
CoCo is the builder surface. Data engineers, developers, and analytics engineers interact with it via Desktop, VS Code, Cloud Agents, and SDK. It builds pipelines, runs tests, modifies schemas, and operates with awareness of the governed data architecture underneath. Cortex Sense gives CoCo the business context it needs to build things that reflect how the business actually works.
CoWork is the knowledge worker surface. Finance, sales, and operations teams interact with it via natural language, Artifacts, and Deep Research. They never see SQL. They interact with governed data through a conversational interface that returns answers grounded in the business definitions Cortex Sense has assembled.
Sridhar Ramaswamy's keynote framing holds across all three: "The model is not your unique advantage. It's when you combine models with your data that things begin to shine." Cortex Sense is the infrastructure that makes that combination reliable at production scale, not just in demos.
What this means if you are building on Snowflake
Three things worth acting on if you are a data team running Snowflake in production.
First, build your semantic views before Cortex Sense reaches general availability. Cortex Sense draws from semantic views as a primary context source. The quality of what it can assemble at runtime is directly proportional to the quality of the semantic definitions you have already encoded. Teams that have built governed semantic views will unlock Cortex Sense immediately. Teams that have not will spend weeks building the foundation it depends on. Semantic View Autopilot is still the fastest path. See our Snowflake Semantic Views practitioner guide for the implementation details.
Second, evaluate CoCo Desktop as the replacement for your current data engineering workflow. The governance-native approach (Snowflake, dbt, Airflow-aware tooling), local sandbox protection, and background Cloud Agents make it a data-native development environment rather than a general-purpose coding agent wearing Snowflake colors.
Third, pilot CoWork with one business team before a broader rollout. The prebuilt finance and sales plugins make this faster than building from scratch. The Artifacts feature is the best demonstration vehicle: instead of publishing a static dashboard, the analyst publishes an Artifact the finance team can interrogate conversationally. That workflow change lands differently than any slide deck about CoWork's capabilities.
The broader point is that Cortex Sense, CoCo, and CoWork together represent Snowflake's answer to the question every enterprise data team faces: how do you get AI into the hands of the business without the business using data incorrectly, without agents bypassing governance, and without the data team becoming a permanent bottleneck between the model and the question?
Cortex Sense handles the context. CoCo handles the building. CoWork handles the consuming. Governance runs through all three because all three inherit from the same Horizon Catalog and access control infrastructure.
Whether this stack fully delivers depends on how quickly Cortex Sense moves from private preview to general availability, and on how deeply your organization has built the semantic and governance foundations it depends on. But the architecture is coherent in a way that earlier Snowflake AI announcements were not. At Summit 26, the pieces connected.
For the data foundation your team needs to build before deploying any of this, see our guide on what a data foundation for AI actually requires. And for the full picture of what Snowflake is building toward at the context layer, see our companion analysis of Horizon Context and what it does to the OSI.
Stay current on AI in data
Hands-on insights on deploying AI agents, LLMs, and automation in real data workflows.

More from Unwind Data
Google's Agentic BI Era With Looker: Why I Think They're Making the Right Bet
Google announced the agentic BI era with Looker at Next '26: BI agents, a native MCP server, Gemini-powered LookML, and the Knowledge Catalog. Here is why I think this is the right move — and the one thing that still determines whether it works.
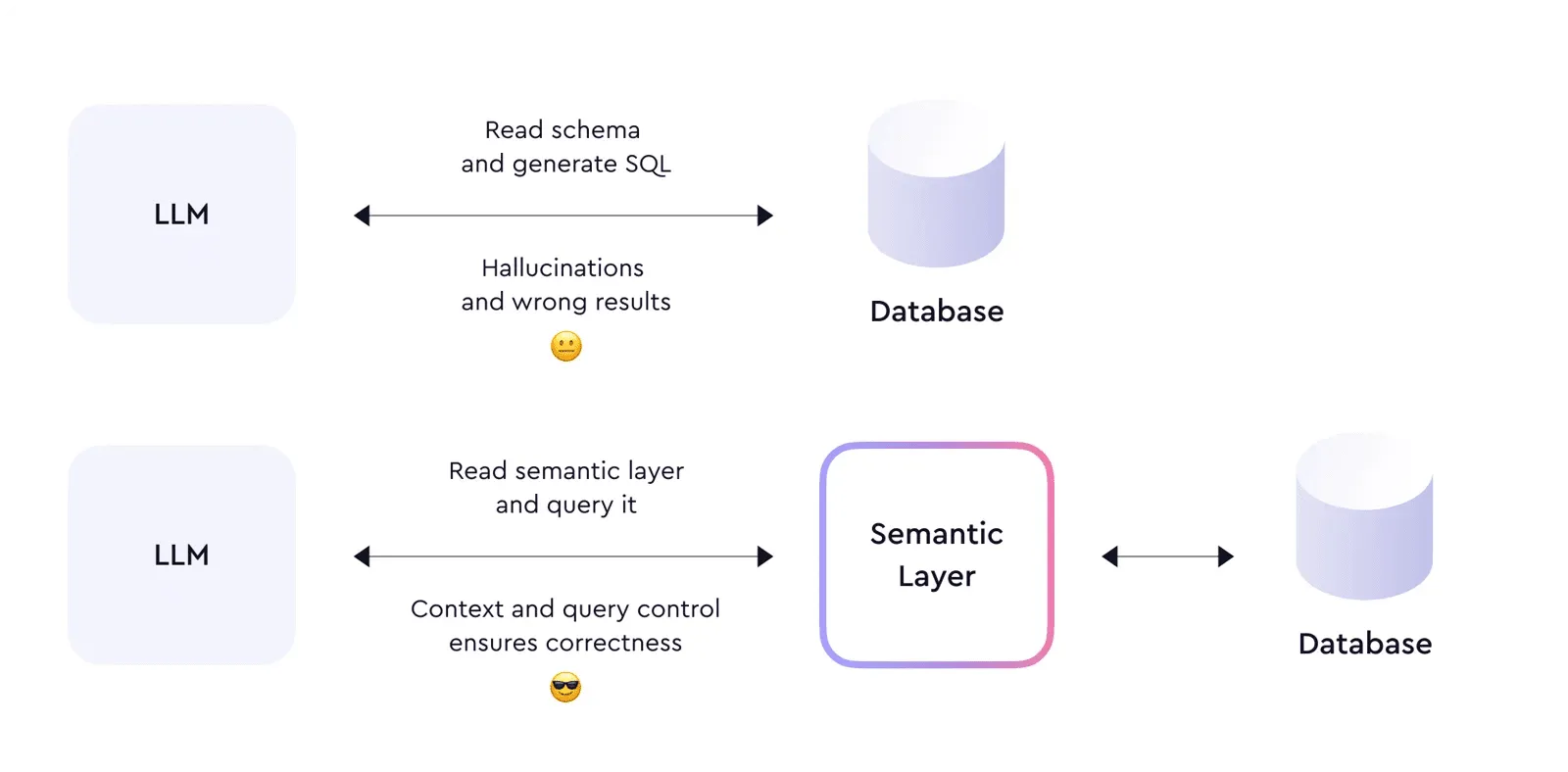
Why AI Agents Hallucinate on Business Data: The Technical Breakdown
AI agents hallucinate on business data not because the model is bad, but because the data layer underneath it is non-deterministic. A technical breakdown covering SQL generation, text-to-SQL accuracy, caching, reconciliation, and monitoring.

Why AI Agent Governance Is Getting Worse, Not Better
75% of companies plan to deploy AI agents by end of 2026. Meanwhile, formal governance policies dropped from 45% to 37%. The problem is not the agents. It is what is underneath them.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch