Best Semantic Layer Tool 2026: A Vendor-Neutral Comparison
The only vendor-neutral comparison of the best semantic layer tools in 2026. No product to sell. Covers dbt MetricFlow, Cube, AtScale, Snowflake Semantic Views, Databricks Metric Views, LookML, and Omni — organized by architecture fit, not feature score.

84% of data teams regularly encounter conflicting versions of the same metric. Not occasionally. Regularly. As in, every reporting cycle, someone argues about whether revenue is gross or net, whether churn is calculated on seats or accounts, whether this week's number matches last week's number.
That is not a tooling problem. That is a semantic layer problem.
And in 2026, it is also an AI problem. When you connect an LLM to a warehouse without a governed semantic layer, you are handing it raw tables and hoping it guesses what your business means by "active customer." It will not. Research shows LLM accuracy on data questions jumps from roughly 40% to over 83% when the model is grounded in a governed semantic layer rather than querying raw schemas. That gap is not a model limitation. It is an infrastructure gap that no amount of model improvement will close.
Every comparison of the best semantic layer tools in 2026 you will find right now is written by a vendor with a product to sell. Promethium puts itself at the top of its own list. Kaelio's CTO recommends Kaelio. Basedash's CEO includes Basedash. That is not analysis. That is marketing in a comparison template.
I have no product to sell. I have been implementing data infrastructure across fintech, e-commerce, SaaS, and sustainability since 2018. I built a Looker practice as a Google solution partner during the $2.6B acquisition. I watched the semantic layer category go from "interesting architecture pattern" to "the thing your AI agents cannot live without." This is what I actually think about the seven tools that matter when choosing the best semantic layer tool in 2026.
Why "Best" Is the Wrong Question
There is no universally best semantic layer tool in 2026. There is only the right one for your architecture, your team maturity, and your downstream consumers.
Every comparison that ranks these tools in order 1 through 10 is misleading, because dbt's semantic layer is genuinely better than Snowflake Semantic Views for one organization and genuinely worse for another. The question is not which tool scores highest on a feature matrix. The question is which tool fits the stack you have, the team you have, and the AI architecture you are building toward.
Start with three questions before you evaluate any tool:
- How many warehouses do you run? If the answer is one, native options become attractive. If the answer is more than one, you need warehouse-agnostic infrastructure.
- Who are your downstream consumers? BI tools, AI agents, embedded analytics applications, and Excel users have very different requirements from a semantic layer.
- Where are you in the Intelligence Allocation Stack? A team still working on data quality at Layer 1 should not be architecting an enterprise-grade semantic layer at Layer 2. Get the foundation right first.
That last point matters more than any feature comparison.
Where the Semantic Layer Sits in Your Stack
I use a framework called the Intelligence Allocation Stack to describe where value actually lives in a modern data architecture. Layer 1 is data foundation: governance, quality, pipelines, warehousing. Layer 2 is the semantic layer: business logic translated for machines, metric definitions, governed vocabulary. Layer 3 is orchestration: pipelines, automations, reverse ETL. Layer 4 is AI: agents, conversational interfaces, autonomous systems.
Most companies skip straight to Layer 4. They deploy AI agents against raw tables and wonder why the outputs are unreliable. The semantic layer is Layer 2. It is the translation infrastructure that makes everything above it trustworthy.
Without a semantic layer, your AI agents are guessing. They do not know that your "revenue" metric excludes refunds and intercompany transactions. They do not know your fiscal calendar runs 4-4-5. They do not know that "active user" means logged in within 30 days for the product team and within 90 days for finance. They will return plausible-looking numbers that are wrong in ways that are hard to detect until a board meeting.
For a deeper foundation on what semantic layers actually do, see What Is a Semantic Layer? The Complete Guide for 2026.
What Actually Breaks Without One
I have been in rooms where the revenue number in the CEO's dashboard did not match the revenue number in the CFO's spreadsheet, and they both said their number was right. Both were, from their respective definitions.
A head of data at a Series C fintech recently told me her team spends three days each quarter reconciling why revenue differs between the sales dashboard, the CFO's spreadsheet, and the product analytics tool. Three different definitions of "active customer." Three different join paths. Three versions of truth that executives argue over instead of making decisions.
That is the semantic layer problem in its clearest form. And it compounds at scale. Organizations now manage 50 or more active data sources. Every new source, every new team, every new BI tool added without a governing semantic layer adds another potential definition of every metric.
The AI dimension makes this existential, not just operationally annoying. When your AI agent joins a meeting, reads the data warehouse, and reports on company performance, you need it to use the same definitions your analysts use. If it is not grounded in a governed semantic layer, it will not. And unlike an analyst who knows to ask for clarification, the AI will just answer confidently.
80% of data practitioners now rank a unified semantic layer as the single most important enabler of AI analytics value, ahead of better models and additional tooling. That number would have been unthinkable three years ago. The category has shifted from nice-to-have to foundational infrastructure.
The Five Evaluation Axes That Actually Matter
Every vendor comparison covers the same criteria: warehouse support, BI tool integrations, governance, performance, deployment model. Those matter, but they are not where implementations succeed or fail. Here is the framework I use.
1. Architecture Fit, Not Feature Count
A tool with 50 connectors is worthless if it does not work well with the warehouse you actually use. A tool with a beautiful GUI is worthless if your team is code-first and every definition needs to live in Git. Match the tool to the architecture and the team, not to the marketing sheet.
2. The Definition Ownership Model
Who writes and maintains metric definitions? If your answer is "data engineers in YAML," dbt is probably right. If your answer is "analytics engineers in a visual canvas," AtScale or Snowflake's Autopilot are worth evaluating. If your answer is "we are not sure yet," pick a tool that does not penalize you for being wrong early.
3. The Downstream Consumer Surface
A semantic layer that only serves one BI tool is a BI tool feature, not a semantic layer. Evaluate how the tool exposes metrics to: traditional BI tools (via JDBC/ODBC), modern BI tools (via REST/GraphQL), AI agents (via MCP), notebooks, and custom applications. The more consumers you have, the more important broad API coverage becomes.
4. The AI Ceiling
The semantic layer determines how far your AI agents can reach. A layer that can express only simple aggregations will cap your AI at simple aggregations. A layer that supports ratio metrics, derived metrics, custom time grains, and complex business rules gives your AI agents more to work with. MCP without a semantic layer is a shortcut that creates reliability problems at scale.
5. Lock-in Exposure
Every platform-native semantic layer (Snowflake Semantic Views, Databricks Metric Views) trades flexibility for simplicity. That is a legitimate tradeoff if you are genuinely committed to one warehouse. But if there is any chance you will add a second warehouse, shift cloud providers, or need metrics consumed by tools outside the native ecosystem, that lock-in will cost you later. Price it upfront.
The Seven Best Semantic Layer Tools in 2026
The semantic layer market in 2026 has consolidated around seven meaningful options. I have organized them by architecture profile, not by ranking, because ranking them in order is not useful.
dbt Semantic Layer (MetricFlow): For dbt-Native Teams
The dbt Semantic Layer, powered by MetricFlow, is the most widely adopted vendor-neutral semantic layer approach in production today. If your team already runs dbt for transformations, this is the natural extension: metrics defined in YAML alongside your models, version-controlled in Git, deployed through the same CI/CD pipelines you already use.
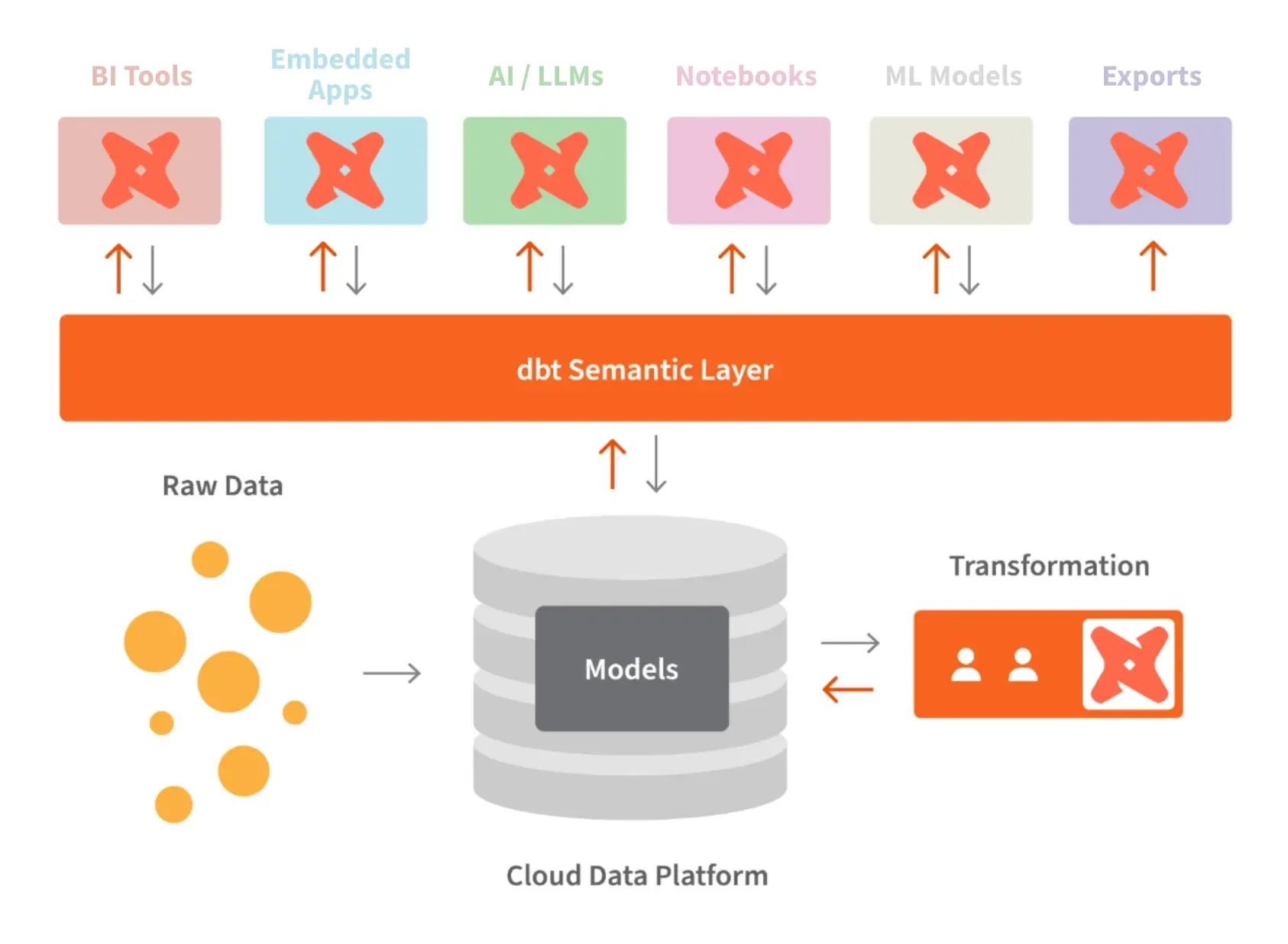
The architecture is code-first and warehouse-agnostic. MetricFlow generates optimized SQL that executes against your warehouse, whether that is Snowflake, BigQuery, Databricks, Redshift, or ten other supported platforms. Metrics defined once flow to Tableau Cloud, Power BI, Looker, and any other connected BI tool through REST API, GraphQL, and SQL interfaces. When a metric definition changes, the update propagates everywhere automatically.
The AI integration is mature. dbt ships an MCP server that lets AI agents like Claude query metrics programmatically with full business context. For an implementation example of how this works in practice, see our deep dive on how MetricFlow turns business logic into infrastructure.
The limitation worth knowing: the semantic layer requires dbt Cloud. If you run dbt Core self-hosted, you cannot access semantic layer features without upgrading to dbt Cloud's Starter tier (currently $100 per user per month, with 5,000 queried metrics included). That is a meaningful cost consideration for smaller teams.
The other real limitation is the learning curve. Teams new to semantic layer concepts find YAML authorship harder than expected. It is not the YAML itself. It is understanding the difference between measures and dimensions, entities and semantic models, ratio metrics and derived metrics. The concepts take time to internalize before definitions start flowing naturally.
Best for: Teams with mature dbt practices, multi-warehouse strategies, and a preference for code-as-infrastructure. Not ideal for teams without existing dbt investment or those who want a visual modeling interface.
Cube: For API-First Teams Building Products
Cube is the leading open-source semantic layer, and it takes a genuinely different philosophical position: headless, API-first, built for teams that are constructing analytics applications rather than connecting BI tools.
The architecture centers on cubes and views defined in JavaScript or YAML. The API surface is exceptional: REST, GraphQL, SQL, Python, and MDX interfaces give consuming applications maximum flexibility. Cube's caching model, built around pre-aggregations that automatically compute and maintain metric combinations, delivers sub-second query performance at scale. Teams building embedded analytics for customers or custom AI analytics applications routinely choose Cube for exactly this reason.
Cube's open-source core (18,000+ GitHub stars for Cube Core) means teams can self-host the full stack with zero licensing cost. That is a significant advantage for organizations with strong DevOps capability and sensitivity to vendor dependency. Cube Cloud's managed offering starts at roughly $40 to $80 per developer per month for teams that prefer not to run infrastructure themselves.
The AI integration story is strong and continues to evolve. Cube provides a dedicated AI API endpoint and a semantic model agent that serves the full data model in a format LLMs can reason over, enabling AI tools to programmatically access governed metrics without custom integration work.
The honest limitation: Cube is genuinely more technical to operate than platform-native options. The documentation is good, but teams without strong data engineering capability will struggle to realize the full potential. The pre-aggregation model is powerful but requires careful design to avoid materialization sprawl. And Cube's traditional BI tool integration surface, while broad, is less polished than dedicated BI-native semantic layers.
Best for: Teams building analytics applications, embedded analytics products, or AI-driven discovery interfaces. Teams that want full control over their infrastructure. Not ideal for traditional BI-centric organizations or teams without dedicated data engineering resources.
AtScale: For Enterprise-Scale Virtualization
AtScale positions itself as a universal semantic layer for large enterprises, and the positioning is accurate. This is the tool for organizations running Fortune 500 data environments: complex dimensional models, multiple warehouses, federated governance requirements, hundreds of analysts using Excel as their primary BI tool.
The architecture is built around intelligent pushdown and aggregate awareness. AtScale sits between your business users and your warehouses, translating incoming queries into optimized warehouse SQL, using pre-computed aggregates when available, and managing the aggregate lifecycle automatically. One major home improvement retailer built a 20+ terabyte semantic model with AtScale, with 80% of queries completing in under one second after implementation. That kind of performance at that scale is the AtScale value proposition in concrete terms.
Where AtScale leads the market is governance depth. Row-level security, column-level masking, object-level security for data mesh architectures, audit trails, and compliance controls are all enterprise-grade. For organizations operating under strict regulatory frameworks or managing sensitive data across organizational boundaries, this matters in ways that dbt's warehouse-native RBAC simply cannot match.
The MCP integration positions AtScale well for the AI agent era. AI agents like Claude can discover and query AtScale semantic models through the MCP protocol without custom integration work, receiving governed results with full business context.
The limitation is complexity and cost. AtScale is not a tool you spin up in an afternoon. It represents additional infrastructure to deploy, manage, and maintain. Enterprise pricing is custom and reflects the enterprise positioning. For smaller organizations or teams without dedicated data platform engineering, AtScale is likely more than what is needed.
A Forrester study commissioned by AtScale found 551% ROI with a two-month payback period. I would treat commissioned ROI studies with appropriate skepticism, but the directional evidence of meaningful return from eliminating duplicate metric logic and reducing query compute costs is credible based on what I have seen in implementations.
Best for: Large enterprises with complex multi-source environments, federated governance requirements, diverse BI tool environments, and Excel-heavy user bases. Not the right fit for smaller teams or organizations without dedicated infrastructure engineering.
Snowflake Semantic Views: For Snowflake-Native Organizations
If you run Snowflake and have no meaningful plans to change, Snowflake Semantic Views are worth a serious look. The proposition is simple: native semantic modeling inside the warehouse you already run, with zero additional infrastructure to manage.
Semantic Views define logical tables representing business entities, then combine them to create metrics and dimensions stored as first-class Snowflake objects alongside tables and views. The YAML-based definition format is consistent with modern infrastructure-as-code practices. Performance is excellent because the Snowflake query engine understands semantic views natively rather than rewriting queries from an external system.
The 2026 addition of Semantic View Autopilot is genuinely interesting. Autopilot uses machine learning to automatically discover metric definitions from warehouse metadata and BI tool usage patterns. Rather than requiring manual definition of every metric, it analyzes how metrics are currently calculated across connected BI tools (Looker, dbt Labs, Sigma, ThoughtSpot) and proposes semantic view definitions. Reducing days of modeling work to minutes in many cases changes the time-to-value calculation meaningfully.
Cortex Analyst, Snowflake's natural language interface, leverages semantic view definitions to ground LLM responses in approved business definitions. For teams already invested in Snowflake's Cortex capabilities for AI, semantic views are the data layer that makes those capabilities trustworthy rather than unpredictable. See our analysis of the Snowflake Universal AI Catalog for the broader context of where this fits in Snowflake's architecture strategy.
The limitation is the ecosystem boundary. Snowflake Semantic Views only function within Snowflake. If any meaningful portion of your analytical data lives outside Snowflake, or if any downstream tool needs to consume metrics via external APIs, the native approach breaks down. The lock-in is real and worth pricing explicitly before committing.
Best for: Organizations genuinely committed to Snowflake as their primary analytical platform, teams that want zero additional infrastructure, and organizations adopting Cortex Analyst for natural language querying. Not suitable for multi-warehouse environments or teams needing warehouse-agnostic metric governance.
Databricks Metric Views: For Lakehouse-Native Teams
Databricks Metric Views, which reached general availability in early 2026, provide the same basic value proposition as Snowflake Semantic Views but for the Databricks lakehouse ecosystem. If Unity Catalog is already your governance layer and your team runs data science, ML, and BI workloads on Databricks, Metric Views integrate naturally.
The architecture separates measure definitions from dimension groupings, letting organizations define a metric once and query it across any available dimension at runtime. This prevents the proliferation of separate materialized views for every possible dimension combination, with the query engine dynamically generating correct aggregations regardless of grouping.
Unity Catalog integration means row-level security, column-level masking, and audit logging of metric access are handled through the governance layer already in place. Organizations do not need to implement a separate security model for the semantic layer. Databricks Genie, the platform's natural language interface, consumes Metric Views to translate business questions into governed SQL within the lakehouse environment.
The honest assessment parallels Snowflake: excellent for the organizations it fits, but Databricks-only. Teams with hybrid architectures, or those needing metrics consumed by tools outside the Databricks ecosystem, will need to supplement or replace Metric Views with a warehouse-agnostic layer.
Best for: Teams all-in on the Databricks Lakehouse with existing Unity Catalog adoption. Particularly strong for organizations where data science, ML, and BI workloads coexist on the same platform. Not suitable for multi-warehouse environments or teams needing cross-platform metric portability.
Looker and LookML: For BI-Native Semantic Governance
LookML is the original production-grade semantic layer that taught the data industry what governed metric definition actually meant in practice. I worked as a Looker solution partner through the Google acquisition, and I will say plainly: LookML is still genuinely excellent at what it does. The question is whether what it does is what you need.
LookML's strength is the tight integration between semantic definition and consumption. Dimensions, measures, and join relationships defined in LookML power Looker's dashboards, explore interfaces, and alert systems directly. When you change a dimension, every dashboard using it updates automatically. That bidirectional consistency between definition and consumption is something standalone semantic layers have to work to approximate.
Google's 2025 to 2026 investment in Gemini integration for LookML is significant. Gemini-assisted authoring generates LookML from natural language descriptions of business logic. Looker Agents use LookML definitions to ground natural language queries in governed business context. Google's internal testing shows LookML reduces data errors in generative AI natural language queries by roughly two-thirds versus raw SQL generation. That is a meaningful number.
For a deeper technical guide to LookML's modeling capabilities and the strategic question of when to use it versus migrating to dbt, see our Complete LookML Guide for 2026.
The limitation is vendor lock-in and multi-BI incompatibility. LookML definitions live inside Looker and can only be consumed natively by Looker. Organizations with Tableau users, Power BI users, or custom application consumers cannot route those consumers through LookML without additional infrastructure. If you run a heterogeneous BI environment, LookML cannot be your only semantic layer.
Best for: Organizations with Looker as their primary (or only) BI platform, especially those invested in the Google Cloud ecosystem. Not suitable as the sole semantic layer for multi-BI environments or organizations planning BI platform changes.
Omni: For Modern BI Teams Who Want Semantic Flexibility
Omni takes a different approach from the dedicated semantic layer platforms: it embeds a flexible semantic layer directly into a modern BI tool, while explicitly allowing that semantic layer to be shared with and consumed by other tools. This matters more than it initially appears.
Omni's semantic model is defined in code (similar to LookML in syntax, but portable) and can coexist with dbt models. Teams using dbt can push semantic definitions into Omni without rewriting them, creating a workflow where dbt handles transformation governance and Omni extends it with BI-level modeling. This is a more realistic architecture for most organizations than a clean separation between transformation and semantic layers.
The MCP integration is worth noting explicitly. Omni ships an MCP server that allows AI assistants like Claude and Cursor to query governed data through natural language against the semantic model. In practice, this means analysts can ask Claude about governed metrics directly in their AI tools without switching to a dashboard. For organizations adopting MCP-native workflows, this closes a meaningful gap. See how Omni's MCP server changes how you query data in Claude and Cursor for the practical implementation picture.
Best for: Modern data teams that want BI and semantic layer capabilities in one tool without the rigidity of legacy platforms. Teams already using dbt who want semantic extensions without committing fully to dbt's cloud pricing. Organizations exploring MCP-native AI workflows.
The OSI Shift: Why Vendor Lock-in Just Got More Expensive
In 2025, an industry initiative called the Open Semantic Interchange launched, with dbt Labs, Snowflake, and Salesforce among the founding participants. The goal: standardize metric definitions in vendor-neutral YAML, so a metric defined once can be consumed by every tool in the ecosystem without translation.
This is not incremental. If OSI reaches critical adoption, the switching cost between semantic layer platforms drops dramatically. Organizations that built metric governance into Snowflake Semantic Views in YAML-compatible formats can migrate that logic to dbt or another platform without rebuilding from scratch. The moat around proprietary semantic modeling languages gets significantly smaller.
The strategic implication is clear: if you are evaluating semantic layer tools now, OSI compatibility should be on your checklist. Tools that define metrics in proprietary formats with no OSI export path are creating lock-in that the market is actively working to eliminate. Tools that adopt OSI-compatible formats are betting on the interoperable future.
For the full picture of who is participating and what it means for your architecture strategy, see our guide to the Open Semantic Interchange and our post on why the semantic layer just became an industry standard.
The AI Agent Dependency Most Teams Are Not Pricing
Gartner projects that 60% of AI projects will be abandoned due to data not being AI-ready. The semantic layer is a central reason why.
When AI agents fail in production, the failure is usually framed as a model problem. The model hallucinated. The model did not understand the business context. The model returned wrong numbers. In most cases I have seen, the underlying issue is not the model. The model is doing the best it can with the information it has. The information it has is raw table schemas with no business context, inconsistent column naming, and no governing definitions of what any metric actually means.
The semantic layer is not a nice-to-have AI feature. It is the boundary that determines how far your AI agents can be trusted. An AI agent operating against a governed semantic layer with well-defined metrics, explicit business rules, and consistent entity definitions will produce reliable results. An AI agent operating against raw tables will produce confidently stated results that are wrong in subtle ways.
The market is waking up to this. 80% of data practitioners now rank a unified semantic layer as the top enabler of AI analytics value, above better models and additional tooling. That ranking would have been reversed two years ago. The practical experience of deploying AI analytics without semantic governance has changed the assessment.
For the governance dimension specifically, our post on which BI platforms actually govern your metrics goes deeper on how different tools handle the definition-to-consumption lifecycle.
What the Vendor Docs Do Not Tell You About Implementation
Every vendor comparison ends with a clean decision matrix and a note that implementation takes four to eight weeks. This section is for people who have actually done it.
The first thing that breaks is the assumption that someone owns the metric definitions. In most organizations, nobody truly owns what "revenue" means. Finance has a definition, sales has a definition, product has a definition, and nobody has ever formally reconciled them. The semantic layer does not fix this. It surfaces it. The first month of a semantic layer implementation is usually a business alignment exercise disguised as a data engineering task.
The second thing that breaks is the dimension model. Most organizations have implicit assumptions about how entities relate to each other that were never formalized. When you try to define a Customer entity that unifies CRM, billing, product, and support data, you discover that Customer means different things in each system. Resolving this is not a semantic layer problem. It is a data foundation problem at Layer 1 that surfaces when you try to build Layer 2.
The third thing that breaks is adoption. A semantic layer that only data engineers can modify is an improvement over no semantic layer, but it is not self-service analytics. Business users and analysts need to be able to trust the definitions and ideally contribute to them. The organizations that get the most value from semantic layers build feedback loops where analysts can flag definition issues and request new metrics through a governed process, not just a help desk ticket.
The practical sequence that works: start with the five to ten metrics that cause the most argument in executive meetings. Define them precisely, test them against known historical values, connect them to one BI tool, and prove the value. Then expand. Trying to model every metric at once is how organizations spend six months building a semantic layer that nobody uses.
Decision Matrix by Team Profile
Rather than scoring tools 1 through 7, here is the decision framework I use with clients when they ask which is the best semantic layer tool for their situation in 2026:
dbt-native team, multiple warehouses, code-as-infrastructure: dbt Semantic Layer. Accept the dbt Cloud dependency and price it against the time saved on cross-tool metric consistency.
Building an analytics application, embedded analytics product, or AI-powered data interface: Cube. The API surface and open-source core are purpose-built for this use case. Self-host on Cube Core or use Cube Cloud depending on your DevOps capacity.
Large enterprise, complex dimensional models, multiple warehouses, Excel-heavy users: AtScale. The additional infrastructure overhead is justified by the governance depth and performance at scale. Get a proper proof of concept before committing.
Genuinely committed to Snowflake as your only warehouse: Snowflake Semantic Views, especially now that Autopilot reduces modeling effort. Accept the lock-in explicitly; do not discover it later.
All-in on Databricks Lakehouse with Unity Catalog governance: Databricks Metric Views. The integration depth is genuine and the simplicity argument is real for organizations already standardized on the platform.
Looker as primary BI platform, Google Cloud-centric stack: LookML is still excellent. The Gemini integration adds genuine AI value. Supplement with a standalone layer only if you have meaningful non-Looker consumers.
Modern BI with dbt compatibility and MCP-native AI workflows: Omni is the most flexible answer for this profile. The ability to coexist with dbt rather than replace it matters for teams with existing transformation investments.
The One Thing Every Comparison Gets Wrong
Every semantic layer comparison treats tool selection as the primary decision. It is not. The primary decision is whether your data foundation is ready to support a semantic layer at all.
A semantic layer built on top of inconsistent, ungoverned data does not produce consistent, governed metrics. It produces consistent, governed transformations of inconsistent data. The garbage comes out clean and clearly labeled, but it is still garbage.
Before you select a semantic layer tool, ask honestly: do you have clean, well-documented source tables? Do you have a clear understanding of how your business entities relate to each other? Do you have ownership over metric definitions at the business level, not just the technical level?
If the answer to any of those is "not really," the semantic layer tool decision can wait. Fix the floor first. The principle I return to constantly: for every dollar spent on AI, six should go to data architecture. The semantic layer is where that investment compounds.
The companies that deployed semantic infrastructure two years ago are now deploying AI agents that actually work. The companies that skipped straight to Layer 4 are the ones explaining to their boards why the AI project did not deliver. The sequence matters more than the tooling.
For the full picture of how this plays out at enterprise scale, see what it actually takes before you deploy AI and our analysis of semantic interoperability as the open standard connecting your data stack.
And then you can tell me what the Best Semantic Layer Tool 2026 is.
Deep dives on modern data engineering
Semantic layers, modern stacks, and scalable architecture — in your inbox, not in a backlog.

More from Unwind Data
AtScale vs dbt Semantic Layer: Enterprise vs Engineering-First
AtScale and dbt Semantic Layer both promise a single source of truth for metrics. But they represent two completely different architectural philosophies and serve two different organizational realities. Here is the head-to-head comparison that vendor demos will not give you.
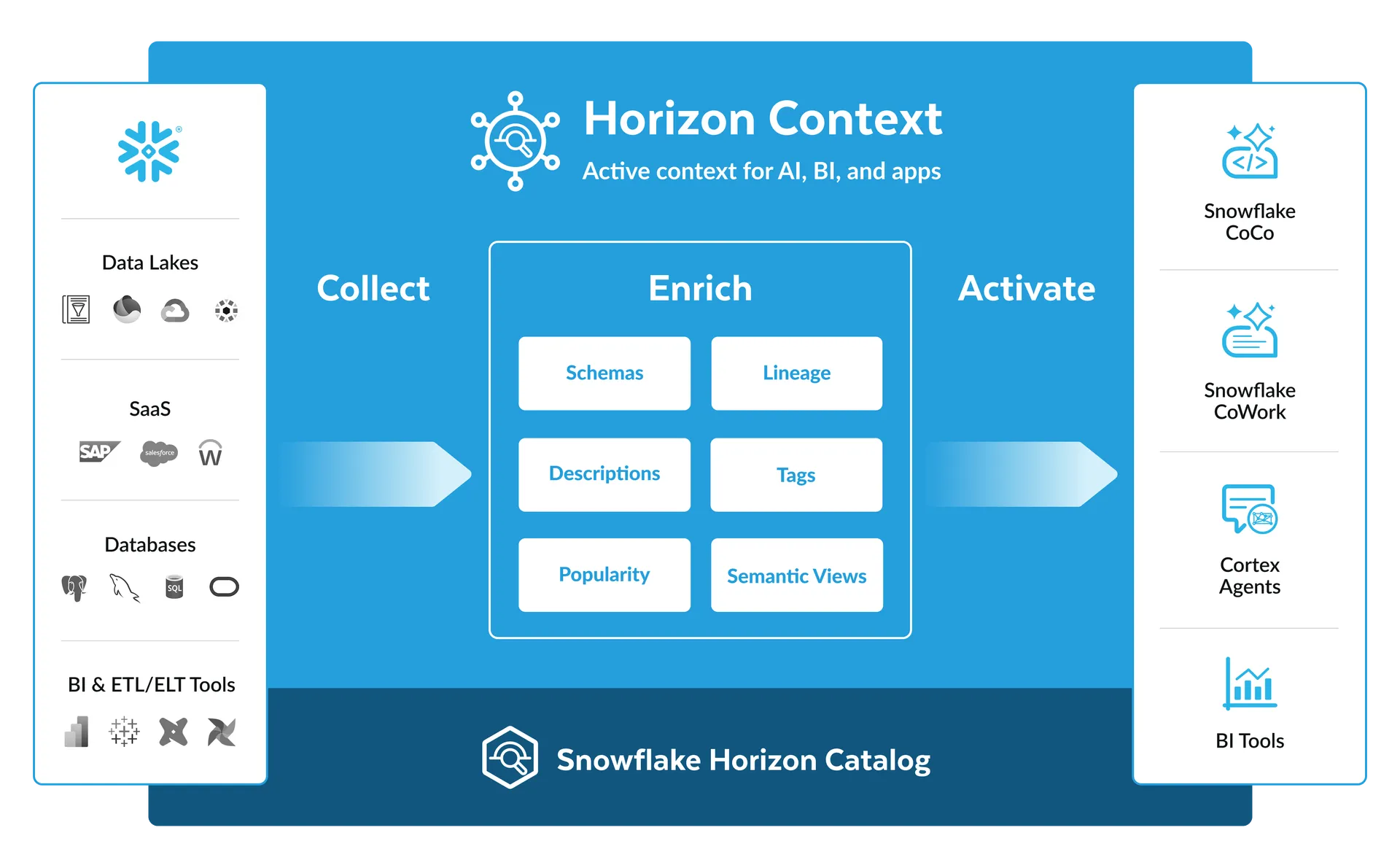
Snowflake Horizon Context: What It Does to the OSI
Snowflake announced Horizon Context at Summit 26: a unified active context layer sitting on Horizon Catalog, serving AI agents, BI tools, and the Cortex stack from one place. Here is what it actually is, and what it does to the OSI question.

Gartner Semantic Layer Warning: AI Agents Will Fail Without Context
Gartner formally warned that skipping semantic foundations will cause AI agents to hallucinate, waste budget, and create governance risk. Practitioners already knew this. Here's what the context layer is and what building it actually requires.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch